本章重点
1. 什么叫非监督学习方法,什么叫有监督学习方法?
2. 非监督学习方法主要的用途
3. 非监督学习方法的两种基本处理方法:按分布密集程度划分,与按相似度聚类划分
4. 按分布密度程度划分的基本方法
5. 动态聚类方法与分级聚类方法的概念
6. 典型的动态聚类方法C-均值算法与ISODATA算法
7. 使用非欧氏距离计算相似度的动态聚类方法
8. 分级聚类方法 本章难点
1. 非监督学习方法与监督学习方法概念的区别
2. 按分布密集程度划分的基本方法
3. 动态聚类方法-迭代修正的概念
4. 分级聚类方法
本章学习指南
在学习本章时首先要弄清本章的主要内容是什么?这要从非监督学习方法的主要任务,与前几章讨论问题的主要任务相对照,从对比它们的差别体会到学习本章的目的,特别是体会非监督学习方法是研究对数据进行分析,在数据中寻找规律的方法学的。
研究数据中的规律性有许多不同的方面。在本章主要是按数据体现的共性将具有相同共性的数据划分在一起,将具有不同共性的数据划分开。找到数据体现的共性才能找到这些数据内在的规律。
将数据按它们表现出的共性进行划分有两种基本方法,从大体上去把按这种不同方法的特点。
在实用中C均值算法等为代表的动态聚类方法,以及分级聚类方法是常用的方法,要重点掌握。
学习中要掌握从易而难的学习方法,如对数据相似度的度主方法最容易的是欧氏距离,然后再扩展到种种非欧氏距离的方法。
本章学习目标
1. 掌握非监督学习方法的概念、用途
2. 了解非监督学习方法对数据划分有两种基本方法
3. 掌握以c-均值算法,ISODATA算法为代表的动态聚类方法
本章课前思考题
1. 如果给机器一维数据,机器能自动地找出其中存在的规律吗?
2. 有人把非监督学习方法叫无教师的学习,而把第二章、第三章讨论的内容成为有监督学习,又称有教师的学习,你知道谁是教师吗?教师的作用体现在哪里?
3. 机器能总结数据中存在的哪些规律呢?
4. 机器能总结天气变化的规律,给出天气预报吗?
5. 机器能炒股吗?
6. 非监督学习方法与数据有关系吗?
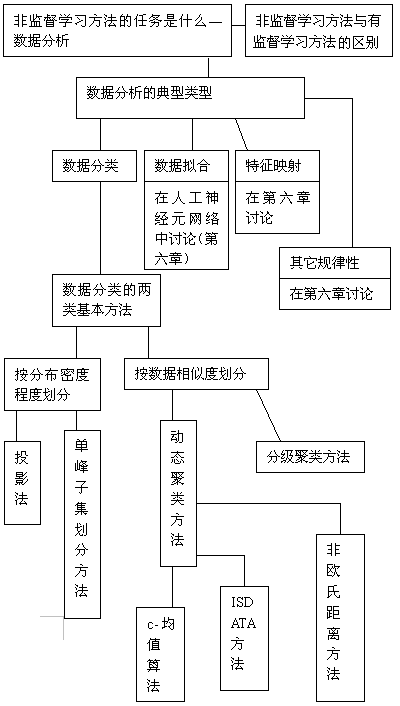
知识树
|