| 此节不作基本要求 从上面所讨论的方法看出,为了兼顾类内离散度与类间离散度,包含在类均值向量内的分类信息并没有全部利用。换句话说,类平均向量的判别信息在K-L坐标系的各个分量中都有反映,并没有得到最优压缩。就拿图4.3的例子来说,如仅从类均值向量所包含的分类判别信息全部被利用这一点出发,应选择包含这两均值向量连线方向在内的坐标系。但是简单地从类均值向量来确定特征子空间,虽然实现很容易,但一般不能满足各分量间互不相关的要求。 有一种特殊的例外情况,这种情况是,如果类内离散度矩阵 |
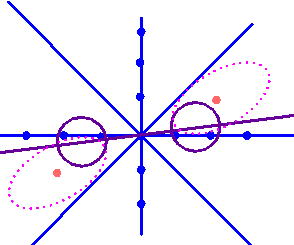 图 4.4 |
| 第一步: 先用原坐标系中 其中 U为 经过B变换后的类间离散矩阵 第二步,以 从而整个变换W为 例 4.3 数据同上例,求保持类均值向量中全部分类信 息条件下压缩为一维特征空间的坐标轴。 今有  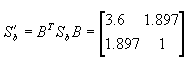
的特征值矩阵是 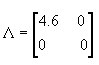 与非零的特征值对应的特征向量是 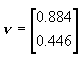 所以  图4.4给出了两次变换步骤以及变换对数据产生的作用。由图中看出,样本原为椭圆形分布,经白化处理后转化为圆形分布,此时 这种方法主要用在类别数C比原D维特征向量的维数D小得多的情况,由于 |