需要指出的是,尽管对不同的判据,具有相同的变换形式,但是这些判据的具体使用仍是不同的。这一点可从J5的进一步分析中看出: (4-15)式表示J5采用(Sw+Sb)及Sw的行列式之比值。由于Sw都是对称矩阵,则通过相似变换可变成对角矩阵。前面已经指出J2,J3与J5在D维空间经非退化线性变换其值不变,因此我们可以通过将J5表示式中的分子,分母都变成对角矩阵来分析,并且希望有
及
其中U为相似变换中用的变换,
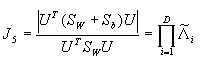 (4-22)
(4-22)其中
如果(4-21)成立,则可写成其逆矩阵形式,有
将(4-23)与(4-20)结合有
可见
因此若用λi表示∧的主对角线各特征,则
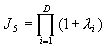 (4-26)
(4-26)与(4-19)相比,可以看出由
至于J3与J1的优点是计算方便,不需要存储任何矩阵。
例4.1给出一个数量的例子,并且说明在两类别情况下,由于Sb的秩只可能为1,因此优化以后的降维特征空间只是一个一维的特征空间,该特征空间实质上就是对应于Fisher准则求得的线性分类器法向量。如果讨论的是多类别问题,则优化后的维数至多为类别数减1。
例4.1给定先验概率相等的两类,其均值向量分别为:
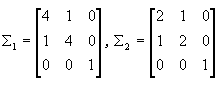
求用J2判据的最优特征提取。
解: 根据前面的分析,应先求
今有混合均值
类间离散度矩阵:
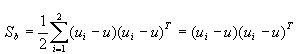
类内离散度矩阵
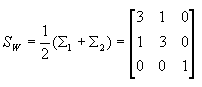
则
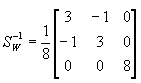
接着,需求
而
由于
因此利用W向量对原始的两维样本进行线性变换,得到新的一维分布,特征空间从两维降到一维,并满足J2判据。