§3.3
非线性判别函数
3.3.1 非线性判别函数与分段线性判别函数
3.3.2 基于距离的分段线性判别函数
3.3.3 错误修正算法
要弄懂这种错误修正算法的原理,首先要弄清值 相比较的含义。我们知道ai与aj代表两类增广权向量,y则代表规范化的增广权向量,这在感知准则函数中已定义过。
相比较的含义。我们知道ai与aj代表两类增广权向量,y则代表规范化的增广权向量,这在感知准则函数中已定义过。
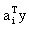 是ai向量与y向量的点积, 是ai向量与y向量的点积,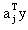 是aj向量与y向量的点积。一般来说点积值比较大则表示这两个向量在方向上比较一致,换句话说向量间的夹角较小。如果某一类样本比较分散,但是能用若干个增广权向量表示,使同一类规范化增广样本向量能够做到与代表自己一类的增广权向量的点积的最大值比,与其它类增广权向量的点积值要大,就可以做到正确分类。因此这种算法就是要用错误提供的信息进行叠代修正。所以它对每类样本集进行具体划分,而希望能知道每类所需的增广权向量数目。当然,实际上,该数目也可以在计算过程中按分类效果调整。
是aj向量与y向量的点积。一般来说点积值比较大则表示这两个向量在方向上比较一致,换句话说向量间的夹角较小。如果某一类样本比较分散,但是能用若干个增广权向量表示,使同一类规范化增广样本向量能够做到与代表自己一类的增广权向量的点积的最大值比,与其它类增广权向量的点积值要大,就可以做到正确分类。因此这种算法就是要用错误提供的信息进行叠代修正。所以它对每类样本集进行具体划分,而希望能知道每类所需的增广权向量数目。当然,实际上,该数目也可以在计算过程中按分类效果调整。
3.3.4 局部训练法
|