学习指南
学习这一章最主要的是了解它在模式识别技术中所处的地位。前一章重点学习的贝叶斯决策具有理论指导的意义,同时也指明了根据统计参数分类决策的方向。沿这条路走就要设法获取样本统计分布的资料,要知道先验概率,类分布概率密度函数等。然而在样本数不足条件下要获取准确的统计分别也是困难的。这样一来人们考虑走另一条道路,即根据训练样本集提供的信息,直接进行分类器设计。这种方法绕过统计分布状况的分析,绕过参数估计这一环,而企图对特征空间实行划分,称为非参数判别分类法,即不依赖统计参数的分类法。这是当前模式识别中主要使用的方法,并且涉及到人工神经元网络与统计学习理论等多方面,是本门课最核心的章节之一。
非参数判别分类方法的核心是由训练样本集提供的信息直接确定决策域的划分方法。这里最重要的概念是分类器设计用一种训练与学习的过程来实现。机器自动识别事物的能力通过训练学习过程来实现,其性能通过学习过程来提高,这是模式识别、人工神经元网络中最核心的内容。
学习这一章要进一步体会模式识别中以确定准则函数并实现优化的计算框架。
由于决策域的分界面是用数学式子来描述的,如线性函数,或各种非线性函数等。因此确定分界面方程,这包括选择函数类型与确定最佳参数两个部分。一般说来选择函数类型是由设计者确定的,但其参数的确定则是通过一个学习过程来实现的,是一个叠代实现优化的过程。因此本章从最简单的函数类型讲起,再扩展到非线性函数。同学们学习的重点要放在线性判别函数的基本内容上,然后再注意如何扩展到非线性函数的应用上去。
该章的学习最好通过概念的反复推敲与思考,以加深对重要概念的理解,另一方面通过实验,亲自体验设计模式识别系统的完整过程,对学习才会更加真切。
数学是模式识别中不可缺少的工具,希望大家学习时,遇到的数学方面的内容要通过再学习、复习等进一步掌握,如线性代数、矩阵的特征值分解与特征向量等概念的运用上起到很重要的作用。通过这门课学习加深对这些数学工具的理解与运用熟练程度是会终身受益的。对于数学推导理解程度的要求,会对增强同学分析问题解决问题的能力有好处。
学习目的
(1) 通过本章学习掌握模式识别中最重要的非参数判别分类法的原理
(2) 掌握机器自学习的原理,自学习功能已不仅在模式识别中应用,目前经常用机器学习这个词以涉及更为广泛的内容。
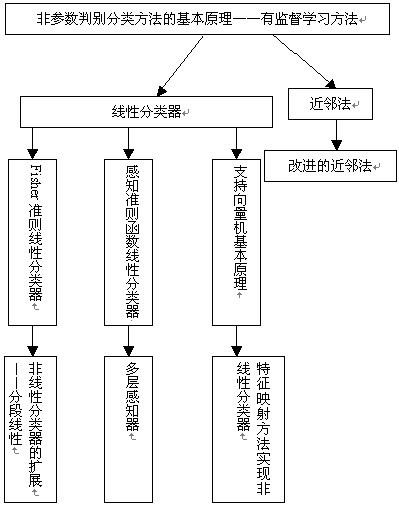
(3) 学习线性分类器的三种典型算法,这三种算法各自形成体系,分别形成了传统模式识别、人工神经元网络以及统计学习理论
(4) 用近邻法进行分类
(5) 通过相应数学工具的运用进一步提高运用数学的本领 本章重点
(1) 非参数判别分类器的基本原理,与参数判别分类方法的比较
(2) 线性分类器的三种典型方法――以Fisher准则为代表的传统模式识别方法,以感知准则函数为代表的机器自学习方法,以及支持向量机代表的统计学习理论。
(3) 近邻法的工作原理及其改进
(4) 线性分类器扩展到非线性分类器,两类别分类方法与多类别分类方法
本章难点
(1) Fisher准则函数,其中用到向量点积,带约束条件的拉格朗日乘子法以及矩阵的特征值、特征向量等数学工具。要求对这些数学工具较深理解。
(2) 感知器准则函数提出利用错误提供信息实现叠代修正的学习原理
(3) 支持向量机方法设计约束条件为不等式的极值优化问题
(4) 三种不同典型方法的优缺点比较
(5) 近邻法的改进
知识点 |