学习指南
这一章的主要内容是说明分类识别中为什么会有错分类,在何种情况下会出现错分类?错分类的可能性会有多大?在理论上指明了怎样才能使错分类最少?另一方面,错分类有不同情况,例如误将A错分为B类,或将B类错分为A类就是两种不同的错误。不同的错分类造成的危害是不同的,有的错分类种类造成的危害更大,因此控制这种错分类则是更重要的。为此引入了一种“风险”与“损失”概念,希望做到使风险最小。要着重理解“风险”与“损失”的概念,以及在引入“风险”概念后的处理方法。
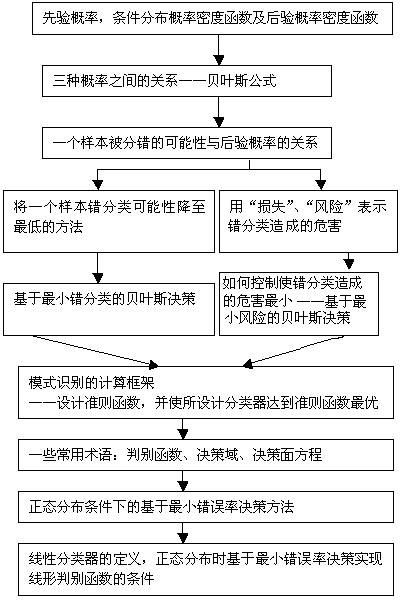
理解这一章的关键是要正确理解先验概率,类概率密度函数,后验概率这三种概率,对这三种概率的定义,相互关系要搞得清清楚楚。Bayes公式正是体现这三者关系的式子,要透彻掌握。
本章讨论的内容在理论上有指导意义,代表了基于统计参数这一类的分类器设计方法,结合正态分布这一例子的目的是使分类器设计更加具体化。学习这一章还要体会模式识别算法的设计都是强调“最佳”与“最优”,即希望所设计的系统在性能上最优。这种最优是指对某一种设计原则讲的,这种原则称为准则。使这些准则达到最优,如最小错误率准则,基于最小风险准则等。设计准则,并使该准则达到最优的条件是设计模式识别系统最基本的方法。
课前思考
1、 机器自动识别分类,能不能避免错分类,如汉字识别能不能做到百分之百正确?怎样才能减少错误?
2、 错分类往往难以避免,因此就要考虑减小因错分类造成的危害损失,譬如对病理切片进行分析,有可能将正确切片误判为癌症切片,反过来也可能将癌症病人误判为正常人,这两种错误造成的损失一样吗?看来后一种错误更可怕,那么有没有可能对后一种错误严格控制?
3、 概率论中讲的先验概率,后验概率与概率密度函数等概念还记得吗?什么是贝叶斯公式?
4、 什么叫正态分布?什么叫期望值?什么叫方差?为什么说正态分布是最重要的分布之一?
学习目标
这一章是模式识别的重要理论基础,它用概率论的概念分析造成错分类和识别错误的根源,并说明与哪些量有关系。在这个基础上指出了什么条件下能使错误率最小。有时不同的错误分类造成的损失会不相同,因此如果错分类不可避免,那么有没有可能对危害大的错分类实行控制。对于这两方面的概念要求理解透彻。
这一章会将分类与计算某种函数联系起来,并在此基础上定义了一些术语,如判别函数、决策面(分界面),决策域等,要正确掌握其含义。
这一章会涉及设计一个分类器的最基本方法――设计准则函数,并使所设计的分类器达到准则函数的极值,即最优解,要理解这一最基本的做法。这一章会开始涉及一些具体的计算,公式推导、证明等,应通过学习提高这方面的理解能力,并通过习题、思考题提高自己这方面的能力。
本章要点
1、 机器自动识别出现错分类的条件,错分类的可能性如何计算,如何实现使错分类出现可能性最小――基于最小错误率的Bayes决策理论
2、 如何减小危害大的错分类情况――基于最小错误风险的Bayes决策理论
3、 模式识别的基本计算框架――制定准则函数,实现准则函数极值化的分类器设计方法
4、 正态分布条件下的分类器设计
5、 判别函数、决策面、决策方程等术语的概念
6、 Bayes决策理论的理论意义与在实践中所遇到的困难
难点
1、 三种概率:先验概率、类概率密度函数、后验概率的定义
2、 三种概率之间的关系――Bayes公式
3、 描述随机变量分布的一些定义,如期望值、方差、尤其是协方差、协方差矩阵,其定义、计算方法及内在含义,透彻掌握其含义才会做到灵活运用。
知识点
|