| 四、分类决策 前面提到模式识别系统工作有两种方式,一种是训练方式,另一是分类决策方式。所谓训练方式是指在已确定的特征空间中,对作为训练样本的量测数据进行特征选择与提取,得到它们在特征空间的分布,依据这些分布决定分类器的具体参数。例如图1.2为一个二维特征空间两类物体的分布状况,其中x1与x2分别为两个特征坐标。由于各类样本分布呈现出聚类状态,因此可以将该特征空间划分成由各类占据的子空间,确定相应的决策分界。一般说来采用什么样式的分界由设计者决定,如上述二维特征空间中可用直线、折线或曲线作为类别的分界线。分界线的类型可由设计者直接确定,也可通过训练过程产生,但是这些分界线的具体参数则利用训练样本经训练过程确定。 |
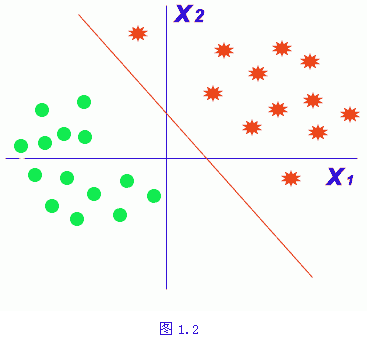 |
| 至于分类决策过程是指分类器在分界形式及其具体参数都确定后,对待分类样本进行分类决策的过程。在图1.2所示的情况中,待识别样本按处于分界线左下方,或右上方分类。 分类决策是对事物辨识的最后一步,其主要方法是计算待识别事物的属性,分析它是否满足是某类事物的条件。对于每个事物来说,由他的属性得到它的描述,表示成相应的特征向量,因此它在特征空间中表示成一个点,称为数据点。一般来说,同一类事物之间属性应比较近似,而不同类事物之间的属性之间应差异较大。这种现象表现在特征空间的分布中往往表现出同类事物的特征向量聚集在一起,聚集在一个相对集中的区域,而不同事物则分别占据不同的区域。因此待识别的事物,如果它的特征向量出现在某一类事物经常出现或可能出现的区域内,该事物就被识别为该类事物。这就是识别事物的基本方法。因此在特征空间中哪个区域是某类事物典型所在区域需要用数学式子划定,这样一来,满足这种数学式子与否就成为分类决策的依据。如何确定这些数学式子就是分类器设计的任务,而一旦这种数学式子确定后,分类决策的方法也就确定了。 以上是对一个典型的模式识别系统几个组成部分最简单与初步的说明。由于模式识别的具体任务是千差万别的,而信息获取与预处理乃至特征选择和提取的具体内容与处理对象密切有关,是各种不同的学科研究与分析的重点,在本书中无法进行深入讨论。因此我们如涉及这方面内容也只是作为举例说明用。本课程将着重围绕模式识别的基本原理及分类器设计的基本问题进行讨论。 另外一点需指出的是,在许多应用领域中模式识别并不一定作为独立的环节存在,如图像处理中包含着许多模式识别的问题,模式识别的原理与基本方法贯穿在许多过程中。但它并没有构成一个完整的独立系统。常见的独立工作的模式识别系统有语音识别系统,文字识别系统等等。 在汽车车牌号码识别例子中我们也可以看到多个模式识别结合在一起的现象。这个例子中包括了车牌区域的识别,车牌类型的识别以及车牌号码的识别,它们是一环接一环的,前一项识别也可看成是后一项识别的预处理。每个识别过程都可用这个框图表示,但各自所用的具体方法是不同的。 |