| 图10.1 目标程序运行时存储区的典型划分 | |||||
|
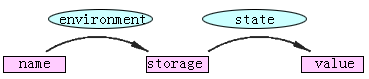
environment函数表示
env: N→S (N到S的映射)
如图10.2所示。
| 图10.2 名字 到存储、到值的映射 |
 |
源语言的结构特点、源语言的数据类型、源语言中决定名字作用域的规则等因素影响存储空间的管理和组织的复杂程度,决定数据空间分配的基本策略。
本章将介绍存储空间的使用管理方法,重点针对栈式动态存储分配的实现进行讨论。
因此运行时的存储区常常划分成:目标区、静态数据区、栈区和堆区,如图10.1就是一种典型划分,代码(code)区用以存放目标代码,这是固定长度的,即编译时能确定的;静态数据区(static
data)用以存放编译时能确定所占用空间的数据;堆栈区(stack and heap)用于可变数据以及管理过程活动的控制信息。
environment函数表示 env: N→S (N到S的映射) 如图10.2所示。
源语言的结构特点、源语言的数据类型、源语言中决定名字作用域的规则等因素影响存储空间的管理和组织的复杂程度,决定数据空间分配的基本策略。 本章将介绍存储空间的使用管理方法,重点针对栈式动态存储分配的实现进行讨论。 |