1.视频服务器中数据的放置策略
(1) 概述
视频服务器存储视频等文件时,必须将数据分块置于磁盘上,每个数据块占用一定的物理磁盘块。通过优化数据的放置,可以减少磁头的寻道时间和响应时间,提高磁盘的带宽利用率,增加时间的吞吐量。
(2) 数据放置策略
① 单个磁盘的数据放置策略
文件块可以连续地或者分散地存放在存储设备中。连续放置易于实现,但容易产生碎片,而且在插入或删除操作时,为保持连续,造成巨大的复制负担。相反,分散放置避免了碎片和复制负担,但实现复杂。连续放置只适用于只读系统,对于需要进行编辑读/写系统则需要采用分散放置。
8.23多媒体存储的数据放置策略
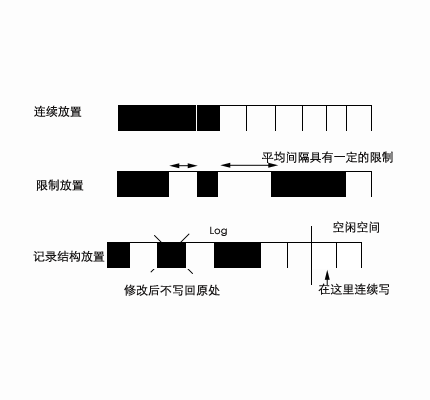
・连续放置(Continuous Placement)。对于连续媒体来说,选择连续放置还是分散放置主要取决于文件内寻道(intra-file seek)。读取连续放置的数据时,只需在数据开头寻道一次,而分散数据则需对每个数据块分别寻道。
・限制放置(Constrained Placement)。避免分散放置中文件内寻道的一个办法是增加数据块的大小,每个时间片读取一个数据块。对于数据块较小的文件系统,文件内寻道仍不可避免。采用限制放置技术,限制连续文件块之间的平均间隔,从而降低平均寻道的时间。
・记录结构放置(Log-structure Placement)。采用这种技术,读/写系统在修改文件块时,并不将修改后的文件块放回原来的位置,而是在一块连续的空间内顺序地执行写操作。这样避免了多次寻道。
图8.23示意了这几种策略的数据放置方法。
② 多个盘的数据放置策略
如果将整个文件存放在一个盘上,那么同时可以访问的数目必然受到磁盘吞吐量的限制。一种解决方法是在几个盘上保持多个备份,不过这种方法过于昂贵。更有效的方法是,将文件分散到多个盘中。这种分散的方法可以由两种技术来实现:条形数据和间隔数据。
8.24 多个盘中文件的放置策略
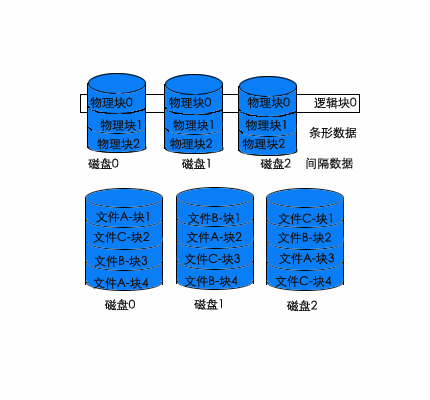
条形数据,如图8.24所示。在RAID技术中得到广泛使用。在RAID技术中,数据成条状分布于多个盘上。每个盘的物理块1被并行访问构成逻辑块1,物理块2合起来构成逻辑块2,……每个盘的访问严格同步,物理块和逻辑块具有相同的访问时间,因此数据传输率得到提高。间隔数据中,文件的各个数据块交错于存储阵列中,连续的文件块存放于不同的磁盘中。每个磁盘异步进行访问,访问时可以按照条形数据的模式,也可以在每个时间片中每个磁盘支持一个数据流。
上面讨论的单个盘的数据放置策略中,与传统文件服务器中的数据放置方法的不同之处在于着重考虑了对连续媒体的支持,尽量减少寻道对性能的影响,实现实时传输。但是,这些策略仍存在许多不足之处有待改进。例如,记录结构放置(Log-structure Placement),并不能保证读取性能,反而增加了实现的复杂性。加外压缩后的每个数据块与物理块并不对应,需要考虑"打包"的问题。而且,对于MPEG-2等可扩展的压缩算法,还应考虑数据怎样放置才能保证有效地提取低分辨率的数据子集来。这些问题都是在解决数据放置策略时应考虑到的。
多个盘的数据放置策略中,条形数据虽然满足带宽的要求,但是并不能提高寻道时间和轮转延时等性能,每个盘的吞吐量仍由读取时间与总时间(加上寻道时间)之比决定。对应间隔数据的放置和访问也需要精心考虑(这对于条形数据是不需要的),以达到整个系统的访问平衡。
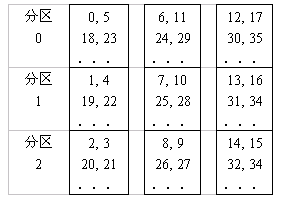
一种改进的数据交错方法是,先对磁盘进行分区。假设有M个磁盘,每个磁盘分为R个区,则对于j=0~M-1,k=0~R-1,I>0,第2RM+2jR+k与第2RM+2jR+(2R-k-1)个数据块位于第j个盘的第k个分区中。图8.25表示了M=3,R=3的数据放置情况。通过分区可以减少平均寻道数据,而循环放置用于优化磁头的移动。
另外,可以考虑将条形数据与间隔数据两种方法结合起来,使数据分布到以网络连接的服务器阵列上,结合冗余技术,从而提高系统的吞吐量。
8.25分区的数据交错放置策略
2.磁盘调度算法
(1) 概述
传统的文件服务器使用了很多的磁盘调度算法,如先来先服务(first come,first served),最短寻道时间优先(shortest seak time first),扫描(scan)等。这些算法主要用于减少寻道时间和轮转延时,获得高的吞吐量,或对每个数据流提高公平的访问。然而由于连续媒体的实时性要求,这些传统的磁盘调度算法不能直接应用到视频服务器上。视频服务器的磁盘调度算法应该在保证每个数据流传输的实时性的基础上,提高系统的吞吐量。
(2) 几种实时的磁盘调度算法
对于具有时限的任务进行调度的一个著名算法是最早时限优先EDF(Earliest Deadline First)算法。这个算法按照数据块访问时取胜的先后进行调度。然而,仅仅根据最早时限优先算法进行调度,可能造成磁头过多的寻道和延时,硬件的利用率不高。
一种改进的算法将扫描与EDF结合起来,称为Scan-EDF算法。扫描算法中,磁头沿盘表面移动,遇到需访问的数据块便进行访问。Scan-EDF算法则根据时限的优先原则选择调度顺序,对于时限相同的请求,采用扫描算法。这种算法在保证实时的条件下,减少了磁头的回溯次数。
其他的算法基本上以轮转形式处理访问磁盘请求。一个循环中,服务器为每个流读取一定的数据。轮转法有效地利用了连续媒体周期性的特点。最简单的一种轮转法是Round-Robin。
视频服务器的磁盘调度算法与传统文件服务器的调度算法不同之处的在于必须满足每个数据流实时传输的需求。因此,这些算法所强调的重点有所不同。
现有的视频服务器磁盘调度算法存在不少问题。Scan-EDF的有效性取决于具有相同时限的请求的数目,而如果在大量请求同时到达,Scan-EDF则退化为Scan算法,不能保证实时性的要求。对于Round-Robin,最大的缺点和EDF一样,在于每次循环时,没有利用数据块的相对位置关系,造成磁头的过多移动。
Scan算法可以减少总的寻道时间,但是对于某个数据流,前一个数据块可能在一次扫描开始时访问,而后一个数据块的访问可能需要等到下次扫描结束,造成流内延时。而轮转法则无法利用数据相对位置的特点。考虑将这两种方法结合起来,形成一种称为分组扫描策略(griuped sweeping scheme)的算法。算法将一个循环中服务的数据流分成几个组,组间具有固定的服务顺序,组内采用扫描的调度算法。但是,GSS算法采用的是线性模型,而线性模型可能导致很大的偏差,这意味着在实现时必须为了最坏情况,使用较大的内存缓冲区。
磁盘调度算法的实现与硬件及操作系统核心驱动程序有关。因此,在设计视频服务器时,只能在这方面做些理论研究和模拟实验。真正实现算法需要和硬盘设计与驱动程序相联系。
3.内存缓冲区管理
(1) 缓冲区大小的考虑
对于单个磁盘来说,同时支持的数据流数目等于磁盘的访问速度除以每个流的数据率。但是考虑到每个文件块的寻道时间,磁盘的平均访问数据率将变为:
其中,B为文件块的大小,Tacc为寻道时间,Rmax为磁盘的最大访问速率。这样磁盘可以同时支持的数据流就大大减少了。若要解决寻道对于性能的影响,每个数据流必须在内存中对应一个缓冲区,缓冲区的一部分用于寻道和磁盘访问,另一部分同时用于传输。设立缓冲区还可以消除磁盘访问及调度过程中造成的数据传输率抖动等问题。
考虑磁盘读取速度是流传输率的两倍以上,可以使用双缓冲区流水线的技术。一个缓冲区用于从磁盘寻道和读取数据,同时另一个缓冲区传输数据。下一个时间单位,两个缓冲区交换功能。这时,每个缓冲区的大小应至少为Tacc*Rt,其中Rt为流的传输率。考虑一般的情况,寻道与读数的时间应与数据传输时间相同,则缓冲区的大小至少应为:
(2) 缓冲区的分配与管理:
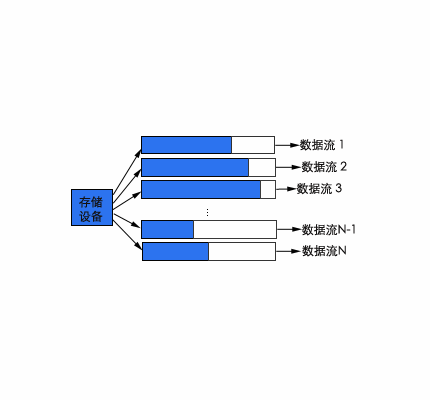
对于每个用户独占固定大小的一个缓冲区的情况,可以想象,刚刚被服务器服务(即从磁盘中读取)的缓冲区几乎是满的,而下一个将被服务的缓冲区几乎是空的。而且,缓冲区被服务之后的时间越长,其中的数据越少(见图8.26)。因此,可以得到结论,缓冲区的整体利用率实际上只有50%左右。
8.26缓冲区的使用模式
根据服务器服务的轮转特点,有人提出了一种改进的缓冲区分配算法。设同样同时支持2N个用户,每个用户按照1~2N的顺序接受服务,则对于i=1~N,第i个和第(2N+1-i)个用户可以共享一个缓冲区,缓冲区的大小比独占的缓冲区略大。图8.27示意了这种改进的缓冲区分配方法。这种方法可以显著地提高缓冲区的使用率,但缓冲区的读/写操作要复杂得多。
8.27改进的缓冲区分配方法

目前的一些研究中,提出了缓冲区池(buffer pool)的概念,不是每个用户独占一个缓冲区,而是所有用户共享一个大的缓冲区。通过共享,使得内存能够得以充分利用。这是一个很吸引人的想法。但是,缓冲区的管理将大大地复杂化。由于每个用户每个时刻占用的缓冲区大小无法确定,数据在内存中的位置很难掌握,这是该思想的一个难点所在。不过,由于内存与硬盘相比,几乎没有所谓寻道时间,所以通过增加数据在内存中的放置复杂性提高内存的利用率,从而降低系统的价格,还是有可能的。
内存是决定视频服务器系统价格的最重要因素之一。由于每个用户需要在内存中占有一定大小的缓冲区,内存的大小与系统同时可以支持的用户数目成正比。目前常用的缓冲区分配算法是每个用户拥有一个固定大小的缓冲区,缓冲区大小由磁盘寻道时间、磁盘访问速度、流传输率等因素决定。这种方法实现起来很容易,但是内存的利用率不高。进一步考虑是使用可变大小的缓冲区,以及共享缓冲区结构。这些算法需要在内存寻址算法等方面详细考虑。
4.流调度算法
(1) 概述
视频服务器一般支持几十个乃至上千个用户,每个用户在获得服务时对应于一个数据流。每个流所传输的数据由用户的选择与请求所决定。从用户发出请求命令到用户接收到数据之间的时间称为初始延时(startup latency或initial delay)。初始延时是决定系统性能的一个重要指标,初始延时越小,系统的交互性就越好。
用户的请求可以分为两种,紧急请求(urgent request)和非紧急请求(non-urgent request)。紧急请求是那种响应延迟要求越小越好的用户请求。如在正进行服务的数据流中用户从一个视频序列切换到另一个视频序列的请求就可以称为紧急请求。紧急请求的响应一般要求在几十个毫秒之内。非紧急请求一般出现于用户开始选择一个新的节目的情况。对于非紧急请求的响应,用户可以忍受1~2秒的延迟。
流调度的算法,其主要功能和目的是通过调度各个数据流的服务顺序,根据请求的类型,使不同的用户请求的初始延时达到最小。
(2) 一种流调度算法
假设时间被分为数个"时间片(slot)"。每个时间片的长度大约等于从磁盘读取一个数据块到存储结点的缓冲区所需要的平均时间。每个数据流传输一个数据块的时间称为一个"帧(frame)"。帧的长度由数据流的输出率与数据 块的大小决定。如数据块的大小为256KByte,数据传输率为200KByte/s,则帧的长度为256/200=1.28秒。如果需要获得更高的传输率,可以将一个帧内的多个时间片分配给一个数据流以达到要求。
对于给定的系统,数据块的大小首先确定。根据基本的流传输率,可以计算出帧的长度。时间片的大小由磁盘传输率、寻道时间大致决定。一般取帧的长度为时间片宽度的整数倍。流调度时,在帧内选择空闲的时间片分配给请求服务的数据流。在不发生磁盘读取冲突的情况下,选择的时间片尽量靠前,以使初始延时最小。
流调度算法对于两类请求具有不同的调度策略。对于非紧急请求,系统在第二个数据块调度完之后再进行第一个数据块的传输。这样,对于数据块大小为256K,流传输率为200KByte/s,初始延时为1.28秒,用户是可以接受的。对于紧急请求,系统在找到满足要求的时间片后,立即进行传输。考虑磁盘的读取速度为4MByte/s,一个256K的数据块在64毫秒之内就可以读出。图8.28示意了两种请求的不同处理。
我们把紧急请求所需的最大延时称为延时目标(latency target),一般以时间片数为单位。当一个紧急请求到来时,在帧内寻找空闲的时间片。若在给定的延时目标内,没有空闲的时间片,则需要用到后移(backword move)与前移(forward move)技术。调度控制将正在传输的数据流在帧中延时目标的范围内向后移,使得空闲的时间片与请求的到来时间的间隔不超过延时目标的要求。若空闲时间片位于请求到来之前,则需要将正在传输的数据流在帧中向前移。图8.29例说明了后移与前移的使用。
8.28 紧急请求与非紧急请求的不同处理
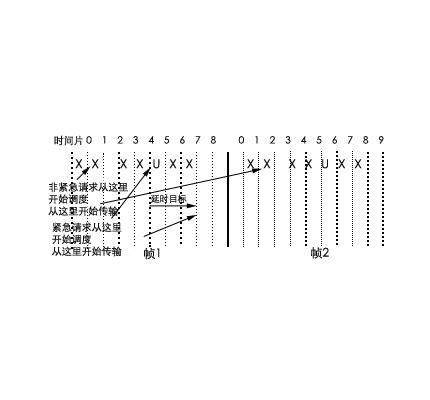
8.29 流调度中的后移及前移技术
通过对不同级别的请求分别处理,并使用后移及前移技术,可以使流调度算法能够较好地满足响应的延时要求。
流调度算法是视频服务器管理与网络及用户接口一个重要的控制算法,它不仅决定了数据流的实时特性,更直接地影响系统响应的延时,最终决定了用户获得服务的性能。因此流调度算法的研究占有重要的地位。
目前视频服务器的设计中,对于流调度的考虑还不是很多,大多数采用的是轮转法进行调度。由于连续媒体的特点,在第一个数据块调度完之后,用户接下来需要访问的数据是可以预测的。所以很多系统采用双缓冲区流水线的方法:一个缓冲区在传输数据的同时,另一个缓冲区已经开始读取下一个数据块了。这种方法的流内延时可以得到保证。
但是,如果用户对数据流进行切换,预先读入缓冲区的数据都失去了作用,流水线负荷下降,延时增加。这与多处理机中流水线结构在指令中遇到分支语句的情况类似。用户的切换命令相当于分支语句,具有多个可能的执行趋势。多处理机结构中,编译器采用延迟转移法、预测转移法、按历史地址转移法等策略。预测指令在分支之后的流向,保证流水线尽可能减少停顿。视频服务器的流调度也可以借鉴这些方法。
流调度算法的性能与上述三个算法有密切的关系,它的具体实现依靠于数据放置策略,内存的分配算法的不同。