HP公司的MAX-2及Intel公司的MMX技术。
1.Motolora公司Phenix芯片
Phenix芯片把可扩展的Power PC的核作为标量处理器和阵列处理器AP(Array Processor)融合在一起,第一代的产品称为向量通信处理器VEComP701(Vector Communication Processor 701)。它可以用在信号处理、3-D图形、人机接口以及图像处理等领域。VEComP 701由两种类型的微处理器组成:一类是单片32位RISC标量处理;另一类是32个16位单指令多数据流(SIMD)并行操作的向量处理器。VEComP 701的功能和特性如下:
・结构可扩充性,用VEComP 701芯片可组成流水线结构,支持1×N个阵列,N最大值是8;
・高性能的标量RISC引擎支持设备驱动、中断处理及命令处理:Power PC单流整数核、32位地址和数据总线,灵活的数据和指令存贮管理、4Kbyte双通道数据Cache地址及4Kbyte双通道指令Cache地址;
・八组存贮控制器:到SRAM,EDO DRAM,EPROM,FLASH和其它设备的接口、具有位屏蔽的32位地址译码。
・系统集成单元:时钟合成器、电源管理器、复位控制器、实时时钟寄存器、优先中断时基、硬件总线监控器和软件时基及IEEE1149.1 JTAG测试存取通道;
高性能SIMD引擎包含16个16位处理元件:每个处理元件是由专用的ALU硬件组成能够同时并行计算数据、每个处理元件有2Kbyte专用存贮器存放本地数据、1KB直接映射向量指令Cache、1KB直接映射向量数据Cache、一个向量处理器时钟周期
VEComP 701 结构框图 (点击查看大图)
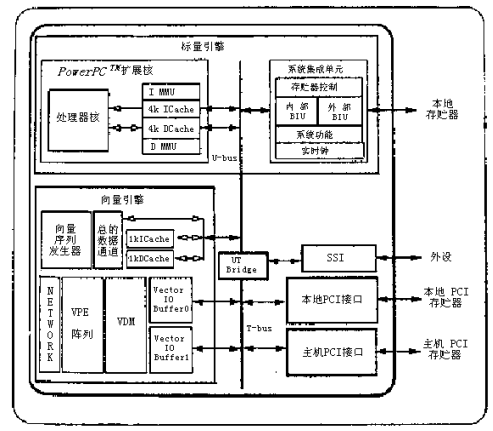
・可执行多条指令及高性能的向量输入/输出缓存(VIOBs);
・两个内部的总线:T Bus和U-BUS;
・总线接口支持工业标准PCI协议;
・芯片中的DMA处理器不需要标量引擎调用可以加速数据传送;
・具有调试查错模块;
・同步串行接口SSI(Synchronous Serial Interface)提供用于多种串行设备的全双功的串行通信,例如工业标准的数据压缩算法(Codecs)、DSP及其它设备。
VEComP 701的基本结构如图5-24所示,它由三个系统组成:标量引擎、向量引擎及外设和系统接口。
(1)标量引擎
标量引擎协调VEComP 701所有的操作,它是由32位Power PC RISC微处理器组成,它调度下述各种任务:
・对于外部数据源的设备驱动器(例如:视频帧获取器);
・在板上各种任务的中断服务;
・为了被动和监视SIMD向量引擎的操作,执行各种通信任务;
・为了执行VEComP701各种应用程序,满足数据传送的需要,标量引擎控制多种DMA的操作。
(2) 向量引擎
向量引擎是由高性能SIMD处理器组成,由数据驱动。它是由向量数据存储器、向量VPE(Vector Processing Element)阵列、向量序列发生器、向量指令和数据Cache以及向量输入/输出缓冲控制器组成,参考图5-24各部分具体情况如下:
(3) 外设和系统接口
VEComP 701用最小的设计复杂性为向量引擎数据传送提供最大的I/O带宽, VEComP 701外设和系统接口包括:
・两个内部总线:T总线和U总线;
・UT桥:它提供T总线和U总线之间的接口;
・测试工具模块:提供应用程序和芯片功能的测试;
・两个向量I/O缓存器(VIOB):为向量数据存储提供I/O控制功能;
・直接数据存取(DMA);
・PCI接口模块:为主机和在PCI总线上的其它设备提供通信功能;
・系统接口单元(SIU):U总线和外设之间接口控制;
・同步串行接口(SSI):为多种串行设备提供全双工串行通道。
2.Intel公司的MMX技术
1996年3月5日Intel公司首先对外公布了MMX技术,它是由设在以色列海法的Intel实验室完成的,1997年1月9日Intel公司对外正式推出含有MMX技术,具有多媒体扩充指令集的多能奔腾处理器P55C,1997年5月Intel又进一步推出了具有MMX技术的P6奔腾芯片,主频可达300MHz的Pentium Ⅱ300,进一步提高了性能。对计算机市场产生了较大的影响,尤其是对多媒体计算机市场,一些PC机厂家认为MMX技术会对多媒体硬件支撑平台带来根本的变化,纷纷推出基于P55C和P6的多媒体计算机。有些厂家认为MMX技术是解决电脑、电信和家电三电一体化的较好的方案,因此积极投入人力和物力研制开发三电一体化的新产品;而另一些多媒体板级产品的厂家出在利用MMX技术设计制造新的多媒体板级产品以适应市场的需要。总之,MMX技术的出现,已对多媒体计算机市场产生了深远的影响。
(1)MMX技术的设计思想
为了改善Intel体系结构IA(Intel Architecture)的多媒体和通信性能以及适应其数字信号处理的应用,Intel公司采用MMX技术扩充IA。为了保持和扩大Intel公司已有CPU芯片的国际市场,MMX技术保证向下兼容性。MMX技术利用SIMD(单指令多数据流)技术,开发了很多算法内部蕴藏的并行机制 ,所以它能比没有MMX技术的CPV芯片运行速度快。
MMX技术的开发者分析了大量多媒体和通信技术的应用软件,包括图形、MPEG视频压缩、音乐合成、音频压缩编码和解码、图像处理、游戏、语音识别以及视频会议,发现虽然它们是不同的应用领域,但是在数据类型和计算方法方面有共性,它们只有简单的数据类型(8位的像素RGB或YUV及2,16位的声音采样数据),定点的矩阵向量运算、局部的循环以及高度的并行性。采用SIMD结构正好能够在一条指令中并行执行多数据流相同的操作,这就是MMX技术能移加速的最根本原因。
另一个设计思想是使MMX技术与现有Intel PC机的操作系统和软件全兼容,因此对MMX的设计不得不加上许多限制,如不能引进新的状态寄存器、控制寄存器及新的条件码等,所以设计者便用浮点寄存器作为MMX的寄存器组。这样设计的原因是:同为浮点寄存器能移提供64位字长,可作定点8位、16位或32位并行运算;另一个原因是保证了与现有应用软件与操作系统的全兼容性。
(2)Intel MMX的核心技术
MMX技术提供了面向多媒体和通信应用的新特性,同时保持了对全部现有Intel体系结构微处理器、IA应用程序和操作系统向下全部兼容,新特性如下:
・增加了新的数据类型;把较小的数据元素的数据类型合并到一个寄存器中;
・扩充了饱和型运算方式:定点运算时上溢下溢不中断,保持最大最小值;
・扩充的57条新指令:扩充的MMX指令系统采用SIMD形式完成寄存器中所有数据元素的并行操作;
・与I A结构的全兼容性:八个64位MMX寄存储组可映射到IA结构的浮点寄存器中。
① 新的数据类型
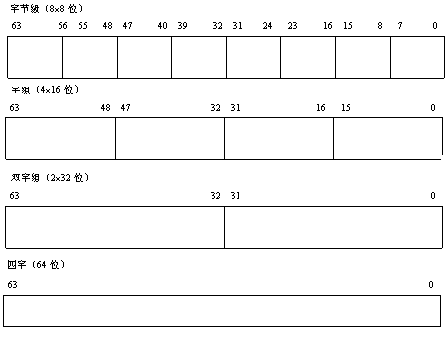
音频采样数据是16位字长,灰度图像的像素数据是8位字长,彩色图像或图形的RGB各分量也是8位字长。如果在一个64位的数据通道中同时处理4个16位数据或8个8位数据,运算速度可以提高到原来的4倍或8倍,同此MMX技术定义了三种打包的(或称紧缩的)数据类型及一个64位字长的类型。在打包的数据类型中每个元素都是定点整数。四种数据类型定义如下(参考图5-26):
a 字节组类型:八个字节组成的一个64位数据;
b 字组类型:四个字组成的一个64位数据;
c 双字组类型:两个双字组成的一个64位数据;
d 四字类型:一个64位数据。
MMX技术可以在一条指令中同时处理8个、4个或2个数据,所以称它为单指令多数据流(SIMD)并行处理结构
② 扩充的饱和型运算方式
定点运算经常会遇到运算结果上溢或下溢。对有符号数运算,上溢指的是结果超过正的最大数,下溢指的是结果比负的最小数还要小。当浮点处理器遇到这种情况时,通常是作为异常情况处理,设置溢出标志并产生中断,由系统软件处理,或者停机交程序员处理,因为这时产生的结果是完全错误的。在图形和图像处理运算中,经常用8位无符号数表示一个像素值或彩色分量值,其最大值255表示亮度最大值(最亮),如果运算结果超过这个值仍然表示为最亮,则是符合实际情况的。但实际上由于溢出进位使其数值变小,图像变黑或变灰,导致与实际情况不符。MMX技术采用饱和式运算方式(Saturation Mode),当运算结果达到最大值时便不再增加,而是保持在这个值。这样就减少了溢出判断处理所需的内部操作而加快了运算速度。另一方面,饱和运算不是一种特殊的操作模式,也不用设置寄存器,它是某些指令操作码的一部分,只在加、减指令中才有饱和方式。例如,对于8位有符号数,上溢和下溢分别置成7FH和 80H;8位无符号数置成FFH和00H。
5-26 成组数据类型 (点击查看大图)
③ 扩充的57条新指令
扩充的丰富的MMX指令系统可以将多种数据元素(8×8,4×16或2×32位定点)编组成64位进行并行操作。共有57条MMX指令增加到原有的IA中,表5-3给出了这些指令的类型及对它们的简单描述。
表5-3 MMX指令系统简表
|
从表5-3中可见,可以把新增加的57条MMX指令分成下述七组:
・算术运算指令
・比较运算指令
・转换运算指令
・逻辑运算指令
・移位运算指令
・数据转移指令
・MMXTM状态置空(EMMS)指令
MOVD(转移32比特)指令将成组的32位比特从内存移到MMXTM寄存器或逆向移动数据,或从整型寄存器中移到MMXTM寄存器或逆向移动数据中。
MOVQ(转移64比特)指令将成组的64位比特从内存移到MMXTM寄存器或逆向移动数据,或在MMXTM寄存器中进行数据移动。
g EMMS(清EMMS状态)指令
EMMS指令将MMXTM状态清空。该指令必须在一个MMX 例程结束时执行。用于清除IA MMXTM(清空浮点标志字),使下一个例程能够执行浮点运算指令。
除EMMS指令外,所有的MMXTM的指令操作均涉及到两个操作数,即源操作数和目的操作数。右边的操作数为源操作数,左边的操作数为目的操作数。目的操作数也可作为第二个源操作数来使用。指令用结果来覆盖目的操作数。
例如,一个双操作数的指令可以按如下方式解码:
DEST(左边操作数)←DEST(左边操作数)OP SRC(右边操作数)
对所有的MMXTM指令来说(除数据转移指令),源操作数可以位于内存和MMXTM寄存器。目的操作数寄存于MMXTM寄存器中。
对于数据转移指令,源操作数也可以是一个整型寄存器(对MOVD指令)或是内存单元(对MOVD和MOVQ指令)。
④ 与IA结构的全兼容性
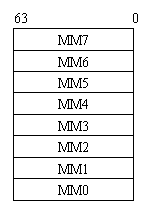
MMX技术提供了8个64位通用寄存器(如图5-27所示),实际上它们是IA中的浮点寄存器,在MMX技术指令中可以通过MM0-MM7直接对它们进行寻址操作。IA MMXTM 寄存器状态是建立在IA浮点寄存器状态上的别名,在MMXTM技术中没有增加新的状态和模式。对浮点状态进行存取的浮点指令,同时也处理了IA MMXTM 状态(例如,在进行上下文切换时)。MMX技术在浮点体系结构和操作系统之间使用了相同的接口技术(主要用于任务切换的功能)。
5-27 MMXTM寄存器集合
(3)MMX技术与奔腾处理器体系结构
在这一节我们将介绍具有MMX技术的奔腾处理器与P6系列处理器如何执行MMX指令流,从中可以了解到为什么这种优化能够提高代码的运行速度,这会帮助我们调度和优化我们的应用程序,以就得更高的运行速度。
①MMX奔腾处理器
奔腾处理器是一个超标量的处理器,它具有两个通用的流水线和一个可流水作业的浮点单元。奔腾处理器在一个时钟内可完成两条指令,一个流水线完成一条指令。一个流水线称为U流水线,一个称为V流水线。在任何一条给定的指令译码期间,将检查后面的两条指令,如果有可能第一条指令被安排到U流水线,而第二条安排到V流水线。具有MMX技术的奔腾处理器为通用流水线增加了额外的处理阶段,具有MMX技术奔腾处理器中MMX指令流如图5-28所示。
5-28MMX指令流

奔腾处理器的流水线只有E,它可以在两条流水线中放有E1、E2……,而具有MMX技术的奔腾处理器指令从代码的高速缓冲区取出后,放到PF预取阶段,并在F提取阶段,对预取的指令字节进行语法分析,对有前缀的指令译码成多至两条指令,并压入FIFO。如果每条MMX指令不超过7个字节则可压入两条指令,指令在先进先出缓冲区中将语法分析与指令译码分开,这个缓冲区位于F阶段与译码1(D1)阶段之间。整数、浮点和MMX指令在D1流水线阶段译码。D2阶段为读取源操作数。E阶段是执行指令阶段。Mex批段为MMX指令的执行阶段,ALU成组移位和分组在读时钟内完成。乘法指令所需的第一时钟阶段,无阻塞条件。WMM2批段为单时钟指令写入阶段,乘法器的第二个时钟阶段,无阻塞条件。M3为乘法器的第三个时钟阶段。WMUL是写乘法器结果的操作阶段,到此一段MMX指令全部完成。
②P6系列处理器
P6系列的流水线由三部分构成:有序组织的前端(In-Order Issue Front-end)单元,乱序内核(Out-of-Order Core)单元和有序的退出(In-Order Retirement)单元。
由于动态执行处理器按乱序的方式执行指令,所以产生了数量充足的、可供执行的微操作,并使大多数有关性能调节方面的考虑得以实现。正确的分支预测和快速的译码是有序前端单元提高性能的核心。
在每个时钟周期内,指令译码阶段可以对多达3条的Intel体系结构宏指令进行译码。但是,如果指令复杂或指令长度超过7个字节,译码器的译码指令数将有所下降。
译码器可以译码:
a每个时钟周期多达三条宏指令。
b每个时钟周期多达六条微操作。
c指令长度大于7的宏指令。
P6系列的处理器在D1阶段上有3个译码器。第一个译码器可在每个时钟周期完成一个由四个以下微操作构成的宏指令,其它两个译码器在每个时钟周期内完成一个由一个微操作构成的宏指令。由多于4个微操作构成的指令将耗费多个时钟周期来完成译码,在使用汇编语言编程时,微操作序列来安排指令将增加每个时钟周期内的译码指令数。通常:
・简单的寄存器--寄存器格式的指令仅用一个微操作。
・读取指令仅为一个微操作。
・存贮指令仅为一个微操作。
・简单的读一修改指令为两个微操作。
・简单的寄存器--内存格式的指令由2-3个微操作构成。
・简单的读-修改-写指令由4个微操作构成。
・复杂的指令通常超过4个微操作,故需耗费多个时钟周期译码。
③高速缓存(Cache)
具有MMXTM技术的处理器的在片高速缓存子系统,是由两个16K的4路线长为32字节的关联高速缓存体构成。高速缓存具有一个回写机制和一个伪LRU的置换算法。数据的高速缓存由8个按四字节边界交错的存储体构成。
在具有MMXTM技术的奔腾处理器上,只要引用的数据不在同一个高速缓存体上,就可以被两个管道同时访问。在动态执行的(P6系列)处理器上,只要引用的数据不在同一个高速缓存体上,就可以被一条读取指令和一条存贮指令同时访问。在具有MMXTM技术的奔腾处理器上,高速缓存访问失败的迟延为8个内部时钟周期。在具有MMXTM技术的动态执行处理器中,最小迟延是10个内部时钟周期。
④分支目标缓存
具有MMXTM技术的奔腾处理器和动态执行处理器在分支预测方面,除一个较小的异常处理外,在功能上完全一样。
分支目标缓冲区(BTB)存贮了预先所见的分支和它们的目标。当一个分支被预取后,BTB将目标地址直接填入到指令读取单元(IFU)。一旦分支被执行,BTB将随着目标地址而改变。使用分支目标缓存时,预先所见的分支被动态预告。分支目标缓存的预测算法包括了模式匹配和每目标多达4位的预测历史位。例如,一个具有4个迭代长度的循环将百分之百地被正确预测到。遵循下列原则将提高预测性能:
・ 编写条件分支(除循环外)可将最常执行的分支紧接在分支指令后(即失败)。
另外,具有MMXTM技术的处理器有一个堆栈返回缓存(RSB,Return Stack Buffer),可以连续地为不同地址上调用的过程,正确地预测其返回地址,进一步为展开具有函数调用的循环带来了益处,并删除了某些需要in-line的过程。
在具有MMXTM技术的奔腾处理器上,如果两个分支指令的最后一个字节在同一个按四字节对齐的内存段内,则分支不可预测。
这种情况,发生在两个相连分支间没有间隔指令且第二个指令只有两个字节长的情况下(如±128字节的相对跳转指令)。
为避免这种无法预测的情况,应使第二分支加长,在分支指令中用16位的相对位移代替8位的相对位移。
⑤写缓存
具有MMXTM技术的处理器具有4个写缓存(相对无MMXTM技术的奔腾处理器的两个写缓存)。另外,写缓存可以被U管道使用,也可以被V管道使用(相对无MMXTM的奔腾处理器的一个写缓存对应一个管道的情况)。通过对内存写操作进行安排调度,可以提高关键循环的性能。如果你不想看到写未命中,每组指令不能安排多于4条写指令。并在安排另外的写指令前调度其它指令。
(4) MMX并发工具和编程技巧
在现有情况下,我们建议采用下述工具和方法。
① 采用在高级语言中嵌入MMX指令的方法:微软的VC+ +4.2和Powersoft/Watcom C是最早以嵌入式汇编支持MMX扩展的C语言编译器。Intel公司自己开发了几乎与MMX指令相对应的C指令库,可以避免记忆繁琐的汇编格式,减少寄存器分配等操作,但是数据流的组织仍然要由程序员完成。
② 采用Intel公司提供的MMX标准函数库:Intel公司现在已经提供了用MMX指令系统实现的、面向多媒体应用的标准函数库:数字信号处理库(DSPL)和模式识别库(PRL)。这些库函数包含了多媒体应用中一些常用的操作,如快速富立叶变换(FFT)、离散余弦变换(DCT)、特征抽取等。这两个库函数较新的V3.0版本是用MMX指令实现的,只要利用6.11D版本的宏汇编语言连接这两个库,就可以利用MMX指令。值得注意的是DSPL和PRL这两个库函数,无论是其标准函数的数量还是执行速度都在随着MMX技术的发展及用户的增加而不断改善。
③ 采用数据流描述方法:传统的算法语言是建立在计算机结构控制流模型上,然而在计算机算法描述中,控制流的描述并不是本质的,例如两个向量的加法既可用循环结构写成,也可以用顺序结构写成,还可以写成混合的折衷形式,而所有这些程序的执行结果都是等效的。保证这些程序功能相同的关键是数据流,也就是说算法的功能被其数据流唯一地确定。基于这种思想,设计了一种数据流描述方法,把MMX的并行性能描述成可以让平行数据流并行通过的数据通道。用这种方法可以很方便地将传统程序转换为MMX程序,并且便于调试。
MMX技术是为了扩充CPU的多媒体和通信功能而设计的,所以它为实现多媒体和通信应用程序带来了方便。最近Intel公司给出了一些应用MMX指令集编程的示例,如彩色键连、向量点积、矩阵乘法、淡入淡出等。我们也用MMX指令集在图形图像领域开发了一些应用程序,例如,RGB到YUV彩色空间的转换、中值滤波及图像边缘提取等,运算速度可以提高3.5~5倍。
MMX主要的编程技巧分述如下
①寻址方式的选择
在奔腾处理器上,当一个寄存器被用作基地址元素时,如果该寄存器是前一个指令的目的寄存器(假设所有的指令都已在预取队列中),将耗费一个附加的时钟周期。例如:
add esi,eax ;esi是目的寄存器
mov eax,[esi] ;esi是基地址,增耗费1个时钟
因为奔腾处理器有两条整数流水线,如果一个寄存器是前一时钟内任意指令的目的寄存器,这个用于计算有效地址(在任一管道)的基地址或索引元素的寄存器,将耗费一个额外的时钟周期。这种效应称为地址生成互锁(AGI)。为了避免AGI,指令间应安排其它指令,并产生至少一个时钟周期的间隔来分隔这些指令。
新增的MMXTM 寄存器不能当作索引寄存器或基地址使用,所以AGI不适用于MMXTM寄存器为目的寄存器的情况。
在AGI情况下,动态执行(P6-系列)处理器不产生额外迟延。
②数据和代码的对准
奔腾处理器和动态执行的P6处理器都有一个32字节行长的cache。由于预取缓冲区在16字节边界进行操作,代码对准对于预取缓冲区的效率有直接的影响。
对于在Intel体系结构下的优化,推荐以下几点:
・如果循环入口标记距离下一个O MOD 16边界小于8字节,则应将这一入口标记置于该边界处;
・条件转移后面的标记不必对准;
・非条件转移或函数调用后面的标记应该进行与第一种情况相同的对准
在Pentium中,数据cache或总线中的非对准访问至少要多消耗3个时钟周期。在动态执行处理器(Pentium Pro系列)中,数据cache的非对准访问要额外消耗9-12个时钟周期。为了在所有的处理器中都得到最好的执行效率,Intel建议数据要进行如下的对准:
・2-byte数据要全包含在对准的4-byte字中(即其二进制地址应为xxxx00,xxxx01,xxxx10,但不可以是xxxx11);
・4-byte数据要对准于4-byte边界;
・8-byte数据(即64-bit,例如双精度实数据类型,所有的MMX紧缩寄存器数据等)必须对准于8-byte边界;
③有前缀的操作码
在Pentium处理器中,指令的前缀会延迟指令分析(parsing)过程和禁止指令的配对执行。下面给出了指令前缀在FIFO中影响:
・以0Fh为前缀的指令没有以上不良影响;
・以66h或67h为前缀的指令要消耗1个时钟周期检测前缀,1个周期做长度计算,1个周期进入FIFO(总共3个时钟周期)。它必须是第一个进入FIFO的指令,后面的指令可以和它一起推入。
・其他前缀(除了0Fh,66h,67h外)的指令要消耗1个多余的时钟周期来检测每个前缀。这些指令仅作为第一个指令时被推入FIFO中。一个有两个前缀指令要消耗3个周期推入FIFO中(前缀的处理需要2个周期,指令要1个周期)。在同一时钟周期中,下一个指令可以和第一个指令一起推入FIFO中。
仅当FIFO中只有一项时,才会产生性能上的降低。只要解码器(D1状态)得到两个指令进行解码,就不会有性能的降低。如果从FIFO中以每个时钟周期两个指令的速度弹出指令,FIFO会迅速变空。这样,如果带前缀指令之前的指令遇到性能缺失(例如,没有指令配对,由于cache不命中引起的阻塞,存储没有对准等),则带前缀指令的额外开销就会被屏蔽掉。
在动态执行(P6)处理器中,长于7字节的指令会限制每个周期解码的指令数。前缀会增加1~2字节的指令长度,从而限制了解码器的性能。
建议尽量不要使用带前缀的指令,或者将它们安排在会引起流水线阻塞的指令后面。
④Pentium Pro系列处理器中的寄存器部分阻塞
在动态执行处理器(P6)中,如果在写1个16-bit或18-bit寄存器(例如,AL、AH、AX)之后紧接着读1个32-bit寄存器,读操作将阻塞,直到写操作完成(至少需要7个周期)。考虑如下的例子,第一条指令将立即数8写入AX寄存器,第二条指令访问了E AX寄存器。这段代码就会导致寄存器部分阻塞。
MOV AX,8
ADD ECX,EAX
由于Pentium Pro系列CPU可不按严格的顺序执行代码,所以不是紧密相连的指令也会引起阻塞。下面的例子就包含了一个寄存器部分阻塞:
MOV AL,8
MOV EDX,0X40
MOV EDI,new-value
ADD EDX,EAX
在第四条指令访问EAX时会发生寄存器部分阻塞。
注意,Pentium处理器没有以上的阻塞情况。
⑤配对
在所有的Intel处理器中,"配对"都是提高执行效率的有效方法。下面给出在Pentium和P6上进行配对的一些原则。在一些情况下,对于特定处理器的性能优化有一些折衷,这些折衷基于应用的特定性质而有所不同。在超标量的Pentium处理器中,指令的顺序对于最大限度地利用性能是十分重要的。
对指令顺序的重排,产生适当的配对,可以增加并发执行(利用U-流水线和V-流水线)两个指令的可能性。有数据相关的指令之间至少要相隔1个其他指令。
下面将讨论MMX指令与整数指令的配对问题,浮点指令是不能和MMX指令配对的。
・ 如果两个指令中有1个长于7字节,Pentium处理器就不能给它们配对。但是,MMX技术的Pentium处理器仅当第一个指令长于11字节或第二个指令长于7字节时无法配对。
・ 带前缀的指令在U-流水线中可以配对。带0Fh,66h或67H前缀的指令也可以在V-流水线中配对。
・ 都要使用MMX移位单元(pack,unpack,和shift指令)的指令不能配对,因为MMX只有一个移位单元。移位操作在U-流水线或V-流水线都可以进行,但是不能同时在1个时钟周期中进行。
・ 都要使用MMX乘法单元(pmull,pmulh,和pmadd等指令)的指令不能配对,因为MMX只有一个乘法单元。情形同前。
・ 访问内存或整数寄存器堆的MMX指令仅可以在U-流水线中使用。所以,这样的指令不能被配对。
・ U-流水线指令的MMX目标寄存器和V-流水线指令的源寄存器或目标寄存器不相同,才可以配对。不然,这种相关阻碍并发执行。
・ EMMS指令不能配对。
此外还有动态分支预测,静态预测,高速缓存优化及内存优化等编程技巧。
总之,MMX程序的开发是一项技巧性很强的工作。MMX技术的利用需要程序员具有良好的汇编语言编程能力,对MMX技术要有深入的理解,同时,还需要在实践中不断总结经验,才能写出高效的代码来。