2.多媒体数据压缩的可能性

我们先来明确一下“信息量”与“数据量”之间的关系:信息量=数据量-冗余量,通常用“I”表示信息量;“D”表示数据量;“du”表示冗余量。
(1)信息量与数据量的关系
I = D - du
其中:I― 信息量, D―数据量, du―冗余量
下面我们来看一下多媒体数据中的“du”,首先看语音数据。“中文广播员一分钟读180个汉字,一个汉字存储两个字节,共需360个字节。采样频率为8kHz(人类语言带宽为4kHz)。
采样1分钟,其数据量为:8K/s×60s = 480 K B/分,一分钟的数据冗余为:480KB/360B=1000(倍)的冗余。”
① 语音数据
中文广播员一分钟读180个汉字,一个汉字存储两个字节,共需360个字节。
采样频率为8kHz(人类语言带宽为4kHz)。
采样1分钟,其数据量为:
8K/s×60s = 480 K B/分
一分钟的数据冗余为
480KB/360B=1000(倍)的冗余
下面我们来看一下图像数据。
图像数据存在着大量的空间冗余和时间冗余。
“例如:下图中的图像“A”是一个规则物体。光的亮度、饱和度及颜色都一样,因此,数据A有很大的冗余。”这样可以用图像“A”的某一像素点的值(亮度、饱和度及颜色),代表其他的像素点。实现压缩。
例如:下图中的图像“A”是一个规则物体。光的亮度、饱和度及颜色都一样,因此,数据A有很大的冗余。

图 4.1.2时域冗余
这是语音数据和序列图像(电视图像和运动图像)中所经常包含的冗余。在一个图像序列的两幅相邻图像中,后一幅图像与前一幅图像之间有着较大的相关,这反映为时间冗余。
例如:图像F1和F2有很大的相关性。
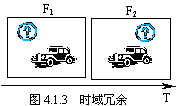
图像F1和F2是两个时刻的图像,路标和小气车的形状与时间相关,没有变化;只是位置发生变化。
除了上述讲述的时间冗余和空间冗余外,我们再向同学们介绍其他几种数据冗余类型:结构冗余、知识冗余、视觉冗余图像区域的相同性冗余、纹理的统计冗余等。
(2)其他的数据冗余类型
① 结构冗余
有些图像的纹理区,图像的像素值存在着明显的分布模式。例如,方格状的地板图案等。我们称此为结构冗余。已知分布模式,可以通过某一过程生成图像。
② 知识冗余
有些图像的理解与某些基础知识有相当大的相关性。例如:人脸的图像有固定的结构。比如说嘴的上方有鼻子,鼻子的上方有眼睛,鼻子位于正脸图像的中线上,等等
。这类规律性的结构可以由先验知识和背景知识中得到,我们称此类冗余为知识冗余。
③ 视觉冗余
人类的视觉系统对图像场的敏感区是非均匀和非线性的。然而,在记录原始的图像数据时,通常假定视觉系统是线性的和均匀的,对视觉敏感和不敏感的部分同等对待,从而产生了比理想编码(即把视觉敏感和不敏感的部分区分开来编码)更多的数据,这就是视觉冗余。视觉冗余是非均匀、非线性的。例:人类视觉分辨率为26,但常用28就是数据冗余。
④ 图像区域的相同性冗余
它是指在图像中的两个或多个区域所对应的所有像素值相同或相近,从而产生的数据重复性存储,这就是图像区域的相似性冗余。
⑤ 纹理的统计冗余
有些图像纹理尽管不严格服从某一分布规律,但是它在统计的意义上服从该规律。利用这种性质也可以减少表示图像的数据量,所以我们称之为纹理的统计冗余。
数据压缩就是将庞大数据中的冗余信息(数据间的相关性)去掉,保留相互独立的信息分量。图像数据压缩是可能的。
4.1.2数据压缩技术的分类
多媒体数据压缩方法根据不同的依据可产生不同的分类。通常根据压缩前后有无质量损失分为有失真(损)压缩编码和无失真(损)压缩编码。有失真压缩是不可逆编码方法,经有失真压缩编码的图像不能完全恢复,但视觉效果一般可被接受;无失真压缩是可逆的编码方法,经无失真压缩编码的图像能完全恢复,没有任何偏差和失真。
1. 按压缩方法分
(1)有失真压缩编码
(2)无失真压缩编码
2. 多媒体数据编码分类如图
3. 按编码算法原理分
(1) 预测编码
(2) 变换编码
(3) 量化与向量量化编码
(4) 信息熵编码
(5) 子带编码
(6) 结构编码
(7) 基于知识的编码
本章在后续的课程中将重点讲述统计编码、预测编码、变换编码、行程编码等。
|