知音文书机是一个集语音识别、语音和语言理解、语音合成以及手写体识别等功能为一体的中文话语系统。它是特定人、孤立音节识别系统。可识别1254个汉语音节。它的最终汉字正确率大于95%,在一般微机上的反应速度大于80字/分钟。该系统共分以下几部分:
①预处理:对模拟语音信号采样,将其数字化,采样频率的选取根据模拟语音信号的带宽依采样定理确定,以避免信号的频域混叠失真。
②特征参数提取:识别语音的过程,实际上是对语音特征参数模式的比较和匹配的过程。语音特征参数的选取对系统识别结果起着重要的作用。因此,必须寻找一个既能充分表达语音特征又能彼此区别的特征参数,这是语音识别中的一个最重要基本问题。语音识别系统常用的特征参数有线性预测系数、倒频谱系数、平均过零率、能量、短时频谱、共振峰频率及带宽等。本系统采用的参数是14维倒谱、14维差分倒谱、能量、一阶差分能量、二阶差分能量,共31维。计算参数时,分析帧长为200,窗移100。
③参数模板存储:在建立识别系统时,首先进行特征参数提取,然后对系统进行训练和聚类。通过训练,系统建立并存储一个该系统需识别字(或音节)的参数模板库。这里声学识别采用基于段长分布的非齐次马尔可夫模型,模板是按半音节建立的,共150个。其中包括103个起始半音,47个终止半音。起始半音用2个状态,终止半音用4个状态。
④识别判决:识别时,待识语音信号经过与训练时相同的特征参数提取后,与模式模板存储器中的模式进行匹配计算和比较,并根据一定的规则进行识别判决,最后输出识结果。本系统首先进行音节识别:从408个音节中选出6个候选,按声调选出2个候选。将起结果提供给理解部分。理解是基于语料库统计方法。假定自然语言符合马尔可夫过程,并认为当前的词(字)只与前一个词(字)有关,则第i个理解单元的概率为:
其中
3.8.3.2. 非特定人语音识别系统
下面简要介绍一个非特定人语音识别系统:非特定人汉语中字表实时识别系统
该系统的词表为208个军事用语。识别采用的参数是16阶CEP系数,分析窗宽为256,窗移128。研究者充分考虑了汉语语音的特点,探索众多话音语音的共性特征及其聚类方法,提出简洁有效的SPM模型。SPM模型是在非线性分块算法的基础上,构造的一个类似于HMM的输出矩阵B:

该模型对不同话者,对语流速度的变异有很强的的适应性,同时还能大大压缩信息量,减少时空开销,保证识别精度。系统识别精度可达99%。
3.8.3.3. 说话人识别系统
说话人识别具有广泛的应用前景,它可分为说话人确认和说话人辨识。
这里介绍的是一个与文本无关的话者识别系统。系统识别分两步进行。首先,使用语音的长时平均FFT频谱作为粗识特征,美(mel)倒谱作为进一步辨识特征,使用GMM(高斯混合模型)描述特征分布。下面简述其基本原理:
①粗识别:
定义第 j 帧语音的FFT频谱矢量
定义长时平均FFT频谱矢量
对于两个平均频谱矢量
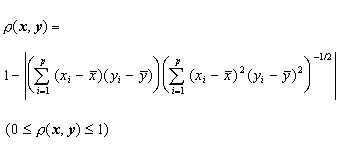
其中:
判别准则:假设x和y分别是说话人X和说话人Y的长时平均FFT频谱矢量。取定判别阈值为
假设闭集辨识系统候选集中的 n 个说话人的长时平均FFT频谱矢量集为
②高斯混合模型(GMM)和精识别
特征矢量的选取:本文采用美化倒谱系数作为特征矢量,它能够有效地表达声道的特征。图3.52是本文辨识系统计算美倒谱系数的框图:
图3.52 计算美倒谱系数的框图
其中:
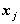 是
p 维FFT频谱矢量;
是
p 维FFT频谱矢量;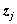 是 d
维美化倒谱矢量。(j=
是 d
维美化倒谱矢量。(j=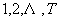 )
)设某说话人的倒谱矢量集
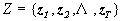 ,高斯混合模型使用如下的概率密度函数描述倒谱矢量
,高斯混合模型使用如下的概率密度函数描述倒谱矢量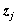 的分布:
的分布: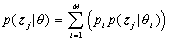 .
. 其中:
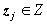 是d维倒谱矢量,j=
是d维倒谱矢量,j=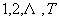 ;M
是模型的阶,即高斯混合模型中单个高斯分布的个数;
;M
是模型的阶,即高斯混合模型中单个高斯分布的个数;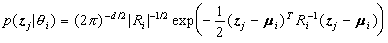
是单个高斯分布的概率密度函数,其参数
 包括均值矢量
包括均值矢量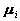 及协方差矩阵
及协方差矩阵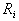 ;
;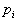 是第
i 个高斯分布的权重,满足
是第
i 个高斯分布的权重,满足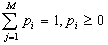 ;
;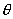 是高斯混合模型的参数,它包括
是高斯混合模型的参数,它包括 和
和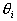 ,i=
,i=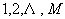 。
。给定集合Z,使用高斯混合模型描述频谱矢量的分布,需确定模型参数
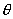 ,使得在该参数下矢量集Z发生概率
,使得在该参数下矢量集Z发生概率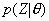 最大。A.Dempster和N.Laird给出了一种EM算法[4]求解参数
最大。A.Dempster和N.Laird给出了一种EM算法[4]求解参数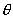 。本文给出该算法的一种简便推导。
。本文给出该算法的一种简便推导。设中矢量互相独立,有
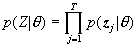 .
.设
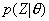 对
对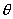 可微,当
可微,当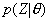 取极大值时满足:
取极大值时满足: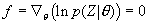 .
.解上式,即可得到估计
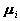 ,
,以
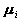 为例:
为例: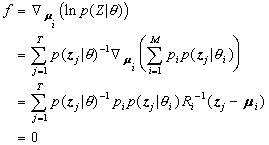
令
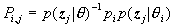 ,
,于是得到
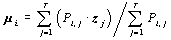 ,将等式左侧的
,将等式左侧的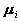 改写为
改写为 ,即得到估计
,即得到估计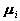 的估值
的估值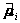 的迭代算法。
的迭代算法。类似地,可以得到
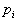 和
和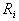 的估值
的估值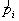 和
和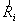 的迭代算法:
的迭代算法: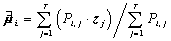 ;
;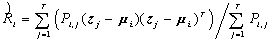 ;
; .
. 判别规则:给定待辨识说话人X的倒谱向量集Z和c个候选说话人
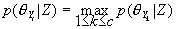 ,则X被辨识为说话人
,则X被辨识为说话人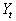 。
。设各候选说话人发生的概率相同,即对任意k(k=
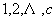 )有
)有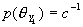 ,据Bayes规则,上述判别式可改写为等价形式:
,据Bayes规则,上述判别式可改写为等价形式: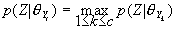 . 在中频谱矢量互相独立的假设下,可以对
. 在中频谱矢量互相独立的假设下,可以对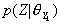 取对数来简化运算。
取对数来简化运算。在不同的
实验表明:
--由长时平均FFT频谱分析和高斯混合模型构成的复合辨识系统能够在较低系统开销下达到好的辨识效果。
--对于说话人辨识,较小的语音预加重系数(例如 =0.50)有较好的效果。
--当高斯混合模型的阶次增加,系统辨识正确率提高,但收敛速度降低。通过分析实验结果,M 取15左右比较合适。
--较长时间的训练和辨识语音有助于提高系统辨识正确率,但训练语音超过60秒,辨识语音超过10秒后辨识正确率提高很慢,因此更长的语音是不必要的。
3.8.3.4 话语系统
话语系统(Spoken Language System)主要由以下三部分组成:语音识别(Speech Recognition)、自然语言处理(NaturaI Language PrOcessing)及人机接口技术(Hunian 1nterfaceTechnology)。它的功能是:先进行语音识别,然后自动翻译,最后给用户以相应回答。
话语系统使得人们可以同计算机讲话,它是用最方便、最自然的语音方式来存取和处理信息。它是人机交互的一次革命。这种接口将让用户使用计算机变得简单方便。采用语音输入,还可提高输入速度。这在一些情况下也十分重要,如:飞行员、外科医生、机床工人、电话用户及残疾用户等,他们可用声音来发出命令。
话语系统在过去的十年里,已有了突破性进展,并获得了一些应用。美国的MIT(麻省理工学院)和CMU (卡纳基梅隆大学)在语音研究方面处于领先地位,其中MIT对话语系统的研究取得了令人瞩目的研究成果。下面简要介绍MIT研制的几个话语系统:
① SUMMIT系统
该系统是一个基于分段的语音识别系统,它采用36维混合状态为64的高斯分布。最后生成的音素网络中,每个状态对应于一个音素,状态的观察值概密函数为高斯函数,每条边由一个所有候选项概率组成的向量描述。
该系统自从1989年推出以来,已经移植到7个领域及3种语言,在最近的ARPA AT1S评测中,它识别单词和句子的出错率分别为4.5%及23.3%。
② TINA系统
该系统是一个自然语言理解系统。它采用概率语法分析,自上而下,基于表的控制策略,使用最大似然分析方法。它的语法规则和相应概率可以从一个语法分析集中自动训练而成。
至今,TINA已经移植到9个领域及4种语言,在最近的ARPA AT1S评测中,它的语句理解出错率为12.5%。TINA与SUMMIT联合起来的话语理解出错率为4.2%。
③ VOYAGER系统
该系统是一个较初级的话语系统,它能与用户进行口头对话,提供关于美国麻省剑桥的地理环境。例如:关于距离、旅行时机、该地区中某建筑物的方位,以及其地址或电话号码等信息。
该系统自从1989年底推出以来,已经移植到3种语言(英、日、意大利),用户在对话中可以混合使用这三种语言。目前,系统使用较小的词汇量及有限的语法知识,就能理解约50%的用户口头提问。为了将该系统作为开发多语言话语系统的平台,专家们正在研究如何从用户的输入中提取出公共的、独立于语种的语义表示形式。
④ GENESIS系统
该系统是一个话语系统的语言产生系统,它既能记录用户的输入问题,又能以语音回答用户的问题。它使用最初由TINA系统建立的语义框架,从数据库中查询返回的信息又不断地增加到语义框架中。该系统由三个模块组成:字典、信息模板集及重写规则集。
它的设计目标为:适用于各个领域及各种语言。目前,它已经移植到4种语言(英、日、意大利、法)上,并且,正在进行德语、西班牙语及中文普通话的研究。
⑤ PEGASUS系统
该系统是连接到美国航空公司EAASY SABRE预订系统的话语接口。系统先从用户提问中提取到充分的信息,以产生一个EAASY SABRE查询语句,该查询一般返回一个格式化表格和菜单供用户选择。这样,系统就将用户的提问对应成适当的菜单项来处理了。
它始建于1993年,目前它已装有关于全球250个主要城市的信息,其识别系统的词汇量达2500词。它可以用自己产生的英语口语,来回答用户关于航线/费用等信息。
⑥ GALAXY系统
该系统是话语系统的一个新的尝试,它在许多方面不同于已有的话语系统。表现在:
・它采用分布式及分散式结构,使用客户机/服务器结构,以便将大量的计算过程(如进行大词汇表的语音识别)及知识密集的处理过程分散到各计算机上执行。
・它可以提供多个领域的、广泛的信息源及服务。并且用户不必知道数据库的详细地址及数据的存储格式。
・它是可扩充的,可以向系统中增加新领域的知识。
・该系统可以从用户处接收语音、键盘及鼠标指定的信息,其输出信息包括图形、文字及合成语音。
通过该系统的研究,可以揭示许多问题。如:"新词"的检测及识别。讲话及对话模型、规模性及可移植性、动态适应性及大词汇表语音识别。至今,GALAXY系统已经应用于3个领域;城市导游(G1TY GU1DE)、航空咨询(AIR TRAVEL)、天气预报(WEATHER)。