MIT媒体实验室采用卷积法计算三维真实感声音,Bill Gardner和Keith Martin在全球信息互连网上放了一套HRTF数据。这些数据由两个tar格式的档案文件和一些描述测量技术及数据格式的文档文件组成。
在三维真实感声音系统中, 数字信号处理算法是由一些简单的运算组合而成的。这些简单的操作包括对输入信号x(n)乘以常数, 加入延迟, 或者在输入信号x(n)上叠加另一个信号。目前用于产生三维真实感声音的基本数字信号处理算法局限性较大。而双耳的HRTF能有效地修改原始波形的谱,且时延增加能使变换后的波形产生三维真实感声音效果。所以其数字信号处理过程是利用双耳的HRTF作为数字滤波器,将原始波形变换到所需要的虚拟声源位置的声音波形。数字滤波器的作用就是将两个波形的谱相乘。则在时间域里表现为两个波形的卷积。用数字公式表示在频率域中就是X(Z)・H(Z),在时间域中x(n) * h(n), 这里 * 表示卷积, 而・表示乘法。HRTF的作用就是将原始声音的谱与耳廓等引起变化的谱相乘。
3.6.4.2 测量方法
MIT媒体实验室所给出的数据是借助于一台Machintosh Qudadra计算机来测量得到的。这台计算机上配置了一块Audiomedia II数字信号处理(DSP)卡, 该DSP卡具有16位双声道的数/模和模/数转换功能, 采样率可达到44.1K赫兹。DSP卡的一路声音输出通过放大器去驱动Realistic Optimus Pro扬声器, 这是一种带有一个4英寸低音喇叭和一个1英寸高音喇叭的小型扬声器, 在测量时还利用了Knowles电子公司生产的一个称为KEMAR的人体模型。这个KEMAR模型仅包含头部和躯于。为了适应不同的研究需要,Knowles电子公司还为KEMAR配置了多种型号的耳廓。 MIT媒体实验室在测量的时候选择了DB-061型作为左耳廓, DP-065型作为右耳廓。在头部里面放置了Etymjtic E-11型麦克风和与之相配的前置放大器, 麦克风和前置放大器的输出通过Audiomedia DSP卡的输入端子输入到计算机中。以Audiomedia DSP卡的输入信号得到的脉冲响应将包括以下诸方面因素的影响:
---数/模和模/数转换器、防混滤波器、扬声器、房间反射、KEMAR模型、麦克风及前端放大器等。
测量的目的是为了获得KEMAR模型的脉冲响应, 尽可能避免其它因素的干扰,如测试扬声器的脉冲响应, 将测出的脉冲响应以反向滤波的形式作为对扬声器脉冲响应的补偿。并假定房间发生反射的时间在麦克风产生响应之后
KRMAR模型的脉冲响应通过最大长度序列(Maximum-Length Sequence)法获得。测量工作是在MIT的消音室里进行的。KEMAR模型放置在一个由马达驱动的可转动的平台上, 这个平台可由计算机控制精确转动到任意一个方位角, 扬声器被安放在一个可自由调节仰角的吊杆上。测试开始时, 首先将场声器固定在某一仰角, 通过不断改变KEMAR模型的方位角来测得各组数据, 整个测量过程中仰角从-40o (低于水平面40o )变化到+90 o (在头的正上方), 以10 o 为步长增量, 共14组仰角, 对于每一组仰角分别测量360 o 方位角中的脉冲响应, 在方位角选定过程中, 并不是对每一个仰角都采用同一步长增量, 表3 给出了每一仰角所对应的方位角数和增量。
表3.15 每一个仰角的方位角数和增量
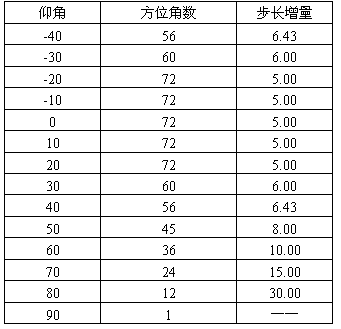
从表3.15 可知, 总共测量了710个位置的脉冲响应。如果KEMAR模型是完全对称的, 并且麦克风也是完全一样的, 那么测量时就只需要测量KEMAR模型的左半边空间或右半边空间的脉冲响应。但是由于采用了两种不同的耳廓, 因此显然左, 右半边空间的响应不尽相同。这种情况下就得出了两组对称的HRTF值。
为了消除干扰因素对HRTF的影响, Gardner和Martin又单独测量了Optimus Pro扬声器的脉冲响应以及多种麦克风的脉冲响应, 这些脉冲响应以反向滤波器的方式作为测量HRTF 的补偿。
3.6.4.3 数据格式
MIT媒体实验室提供了两套数据, 一套称为完整数据(Full Data); 另一一套称为紧凑数据(Compact Data)。这两套数据分别存放在Full目录和Compact目录里。
完整的HRTF数据以仰角目录存放的, 每个目录名都是诸如"elevEE"形式, 其中EE是仰角值。在Full目录里一共有14个子目录, EE的取值如表3所示。在每一个仰角子目录里存放的数据文件, 每个文件名的形式是"XEEeAAa.dat", 其中X为L或R, 表示该文件中的数据是左耳还是右耳的脉冲响应, EE是仰角值, 它等同于该子目录名中的EE值, 范围从-40到90, AAA是方位角的值, 它的范围从0至355。一旦仰角和方位角给定了, 那么声源和KEMAR模型的相对位置也就固定了。当仰角为90o 时表示声源在KEMAR模型的正右方。因此象"R-20e270a.dat"这个文件中的数据就是当声源在耳朵所在水平面以下20度, 正对左耳时的右耳的脉冲响应。
每个文件中的脉冲响应共512点, 每一点是一个16位的有符号整数, 其高八位存放在地址较低的地方。左耳脉冲响应的最大绝对值为26793, 在文件"L40e289a.dat"中, 其值为-26793, 在耳脉冲响应的最大绝对值为29877, 在文件"R40e039a.dat"中, 其值为29877。
紧凑数据是以128点存放的, 它是对那套完整数据的左耳脉冲响应删除其中的一些点而得到的。紧凑数据同完整数据一样, 也是按声源的仰角值为子目录名存放的, 所不同的是在每个子目录中文件名的形式为"HEEeAAAa.dat", 其中EE为声源的仰角值, AAA是声源相对于KEMAR模型的方位角, 每个文件中存放了128对脉冲响应, 分别对应于给定声源位置下左耳和右耳的脉冲响应。例如文件"H0e090a.dat"中存放着声源位于水平面上正对KEMAR模型左耳时KEMAR模型的左耳和右耳的脉冲响应, 其中左耳的128点脉冲响应数据是取自于完整数据中的文件"L0e090a.dat", 而右耳的128点脉冲响应数据是取自于完整数据中的文件"L0e270a.dat", 对紧凑数据而言, 每个脉冲响应也是以16位整数存放的, 其左、右耳的脉冲响应值是交替存放的。在紧凑数据中其最大值为30496, 在文件"H-10e100a.dat"中。
3.6.4.4 卷积法计算三维真实感声音
MIT的媒体实验室提供的数据所对应的DSP系统实际上是一个FIR。要获得指定位置发出的虚拟声效果, 只需将一个原始的输入声音信号卷积按给定位置查找出的脉冲响应数据。卷积法生成三维真实感声音算法描述如下:
输:入: 1) 原始声音文件
2) 虚拟声源相对于头部的方位角和仰角
输出: 用于驱动两个耳机的三维真实感声音文件
Begin: (1) 查找脉冲响应数据
根据给定的方位角和仰角, 找到相应的数据文件, 读出后将其存放在一个数组h[0…5]里
(2) 计算卷积
采用的方法是移位相加法, 其代码描述如下:
for (I=0; i<n+512-1; I++)
y[i]=0;
for (I=0; I<512; I++)
for (j=0; j<n; j++)
y[i+j]=y[i+j]+x[j]・h[i]
其中数组x[ ]中存放的是输入信号, 其长度为n; 数组h[ ]中存放的是脉冲响应信号, 其长为512; 数组y[ ]中最终将存放输出声音信号, 其长度为n+512-1。
(3) 数据删减
可根据实际需要适当地将数组y[ ]中的数据前后各删除一些, 以保证最后声音效果。通常如果脉冲响应信号512点的话, 将输出声音信号前后各删除256个点。
End
卷积法生成三维真实感声音的优点是算法简单, 生成出来的输出声音信号效果逼真, 但其最大的缺点是计算量大, 用软件实现的话,根本不可能达到实时性的效果。卷积法适用于硬件实现三维真实感声音的生成。实际上卷积计算就是一个Toeplitz矩阵与一个向量的乘积。到目前为止,最好的计算方法就是用快速傅立叶变换来计算, 但对于脉冲响应为512点的问题来说,效果并不比移位相加好, 除此之外文献中未见到有更好的快速计算方法。从另外一个角度讲, 研究Toeplitz矩阵与一个向量乘法的并行计算方法也许会对本问题提供一种可行的软件实现途径。