听阈是指人能听到的最低声压级。纯音的听阈与频率有关。1KHz纯音的听阈约为4dB, 10KHz 时约为 15dB。当声压级增大到一定强度时, 人耳会感到不适(不适阈)或疼痛(痛阈)。
人耳对不同频率纯音的听辨灵敏度不同。图3.5表示人听到同样响度的声音时, 其声压级与频率的关系。每条曲线都是一条等响曲线。
图3.5 等响曲线
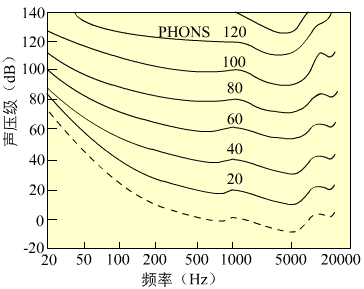
从图中看出,人对声音响度的感觉, 与声音的强度和频率有关。而且当两个响度不同的声音作用于人耳时, 则响度较高的频率成分会影响对响度较低频率成分的感受。这种现象称为人耳的掩蔽效应。从频率角度来看, 低频成分容易掩蔽高频成分。而且掩蔽效应使被掩蔽频率成分的听阈上升。
一种频率的声音阻碍听觉系统感受另一种频率的声音的现象称为掩蔽效应。前者称为掩蔽声音(masking tone),后者称为被掩蔽声音(masked tone)。掩蔽可分为频域掩蔽和时域掩蔽。
频域掩蔽是指一个强纯音会掩蔽在其附近同时发生的弱纯音。
除了同时发出的声音之间有掩蔽现象之外,在时间上相邻的声音之间也有掩蔽现象,并且称为时域掩蔽。时域掩蔽又分为超前掩蔽(pre-masking)和滞后掩蔽(post-masking)。产生时域掩蔽的主要原因是人的大脑处理信息需要花费一定的时间。
一个纯音可能被另一频率的纯音所掩蔽。当掩蔽声出现时,被掩蔽声就听不到了。要想听到被掩蔽声,就要提高它的阈值。掩蔽声越强,被掩蔽声的阈值越大。
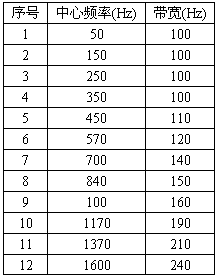
噪声的存在也会影响纯音的接收, 即对纯音产生掩蔽。一个纯音处于以它为中心频率, 具有一定频带宽度的连续噪声中, 如果在这一频带内,噪声功率等于纯音的功率, 则此纯音可能刚好被掩蔽。这时, 纯音处于则能被听到的临界状态, 则称之为连续频带的带宽为临界带宽。表3.4给出了25个临界带宽的编号、中心频率以及高、低临界频率。
表3.4 临界频带
人的听觉是一个复杂的感知过程, 涉及到听觉、理解、先验知识等, 这里讨论的是语音信号对听觉感知的影响, 如上述的强度、频率、掩蔽。
人们把听觉模型引入语音的感知编码的研究中。鉴于共振峰对噪声的掩蔽效应,使得降低共振峰区的信噪比,也不会影响听感效果。由此可知,最佳失真(即噪声)即不是白噪声, 也不是与输入语音频谱类似的谱(图3.6中的虚线), 而是介于二者之间即有语音特点又类似于白噪声的频谱(实线所示)。对于相同的失真率(图3.6中曲线下部区域), 这种类似白噪声的声谱最大限度地利用了共振峰的失真掩蔽作用
图3.6 语音编码中噪声谱的构形
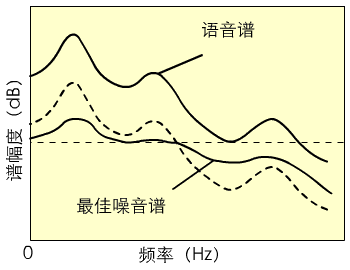
观察图3.6可以看出, 在第三共振峰频率处的信噪比太小, 以致不能掩蔽高频范围内的失真, 实际上此白噪声谱是次最优的。其次, 尽管似语音的谱在第三共振峰处提高了SNR(信噪比), 但这是以降低第一共振峰处的SNR为代价的, 因为损害了编码在低频范围的保真度。而中频段最优, 它是在不损害重要的低频特性的前提下, 在整个频带上达成了一种平衡。这个频谱是一个MND分布(minimally noticeable distortion)。
图3.6中的MND分布是一个平滑的频谱包络。它的好处在于容易与LPC的谱包络一致。特别是在生成最优噪声构架时, 增加的额外计算很少, 在形成感知谱结构的不需附加的比特率。但这种MND包络没有与说话者基频相关的频谱结构。
图3.7中,用一个简单的例子表示优化频率分析带来的益处。这个例子不是来自CELP编码, 而是来自自适应变换编码。图中的纵、横坐标是比特分配和频率。比特分配算法(和与之相应的噪声构形)依据上图平滑谱模型和下图优化谱分析(包括基音信息在内)中获到。这两例中的总比特数相同。但上图中, 算法响应了平均谱能量, 并把全部比特分配给语音的低频段。它以损失高于2.3KHz(第三共振峰)以上的频率成分为代价, 给予低频段过多的码位。下图中通过优化分析, 算法识别低频段由基频结构引起的波谷。实际上,它的能量比高频段的基频峰还小。
图3.7 优化频率分配的益处
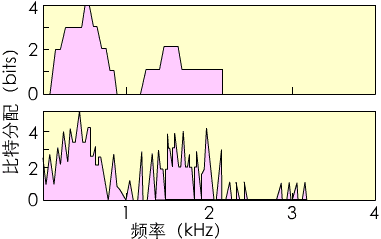
用这个信息为选中的高频分配量化比特 (如图中在3KHz处的4个峰)。换句话说, 通过响应选化分析的局部能量线索, 保留了语音信号中重要的高频部分。这里描述的是基于能量线索, 还不是噪声掩蔽原理: 但优化频率分析的优越性越过了噪声屏蔽法。强化了人们对局部频率分析器的需求。
表3.5 描述的是作为语音频率的函数的清晰度指数(它是清晰度的一种度量), 当频率低于200Hz时, 尽管可能改善自然度和逼真度, 但无助于清晰度。该表也显示出尽管高于传统电话3400Hz的语音能量很低,但对清晰度是重要的。视频会议期望高质量的语音对话,因此,宽带语音编码是非常必要的。
表3.5 语音频带与清晰度的关系
|
(2)感知加权:
利用听觉的掩蔽效应,设计频域感知加权滤波器
在能量较高的频段,
在能量较低的频段,
以保证总体误差 e 最小:
其中
可以证明:要使 e 达到最小,
通过调整激励参数, 可以达到使 e 达到最小的目的。
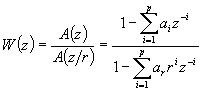
其特性由预测系数
r=0:
此时,误差谱的包络与语音谱包络类似, 听感效果不好。
r=1:
此时没有进行感知加权。
的作用使实际误差信号的谱不再平坦, 而是有着与语音谱相似的包络形状使共振峰对误差的掩蔽效应相一致, 产生较好的主观听觉效果。
实际应用中,
当处理10Hz-20000 Hz范围的声音时,数据压缩主要依据是人耳的听觉特性,使用"心理学模型(psycho acoustic model)"来达到压缩声音数据的目的。
心理学模型中一个基本的概念就是听觉系统中存在一个听觉阈值电平,低于这个电平的声音信号就听不到,因此就可以把这部分信号去掉。听觉阈值的大小随声音频率的改变而改变,每个人的听觉阈值也不相同。大多数人的听觉系统对2KHz-5KHz之间的声音最敏感。一个人是否听到声音取决于声音的频率,以及声音的幅度是否高于这种频率下的听觉阈值。
心理声学模型中另一个概念是听觉掩饰特性,即听觉阈值电平是自适应的,也就是听觉阈值电平会随听到的不同频率的声音而发生变化。例如,同时有两种频率的声音存在,它们的强度不同,分贝低的声音就听不到。比如在一个安静的房间可以听到我们普通的谈话声音,但在播放音乐的环境下同样的普通谈话就听不清楚了。
所以,声音压缩算法可以确立这种感知加权特性的模型来消除更多的冗余数据。