① 自适应量化PCM (APCM)
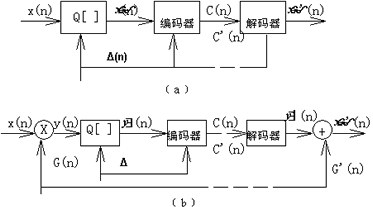
除了瞬时压扩外, 还可以用自适应量化的方法来解决均匀量化中遇到的困难.自适应量化的基本思想是使量化器的性质自动适应输入电平。一种方法是让阶距△(n)变化,使之与输入信号方差相匹配,如图3.3a所示。这意味着阶距随输入信号方差而增减。它也是个非均匀量化器。另一种方法是在固定量化器前,加一个自适应增益控制单元,以使输入到量化器的信号方差相对地保持恒定,如图3.3b所示。
在两种方法中,都需要随时估计输入信号的时变幅度,以修正量化阶距或增益。由于估计阶距和增益的方法不同,得到两类自适应量化器。一是输入信号幅度或方差由输入信号本身估计,这称为"前馈自适应量化器";另一类是输入信号的方差由量化器输出或等效地由样本码序列来估计,这称为"反馈自适应量化器"。通常,任何一类量化器的自适应时间都可以是音节的或瞬时的。
图3.3 自适应量化框图
自适应量化方案几乎有无限的可能性, 但不能大幅度地降低比特率。
自适应量化PCM (adaptive pulse code modulation , APCM)是一种根据输入信号幅度大小来改变量化阶距大小的一种波形编码技术。这种自适应可以是瞬时自适应,即量化阶距的大小每隔几个样本就改变,也可以是音节自适应,即量化阶距的大小在较长时间周期里发生变化。
改变量化阶距的大小有两种方法:一种称为前向自适应(forward adaptation),另一种称为后向自适应(backward adaptation)。
前向自适应是根据未量化的样本值的均方根值来估算输入信号的电平,以此来确定量化阶距的大小,并对其电平进行编码作为边信息传送到接收端。
后向自适应是从量化器刚输出的过去样本中来提取量化阶距信息。由于后向自适应能在发和收两端自动生成量化阶距,所以它不需要传送边信息。
② 差值量化
研究表明,相邻语音样值之间存在着很大的相关性,即从一个值到相邻另一样值,信号不发生迅速变化,因此相邻样值之差的方差比信号本身的方差要小。这一事实的最简单应用是增量调制(DM)。在DM系统中,采样率比奈奎斯特频率高许多倍,量化器只有一位码。
利用差值量化理论构成的量化方案如图3.4。在此系统中,量化器的输入为:
图3.4 一般差值量化框图
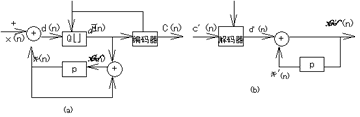
(a)编码器 (b) 解码器
d(n)表示输入样值X(n)和输入样值的预测值 之差。这个预测值是预测器P的输出。
量化后的差值信号表示为:
由图中看出:
则:
上式表明,量化的输入样值 (n)与输入信号x(n)之差仅仅是差值信号的量化误差。那么如果预测器性能优越,d(n)的方差将比x(n)的方差小得多,则对d(n)量化的误差也将小得多。
图3.4系统的信噪比:
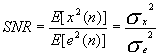
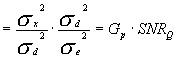
其中SNRQ是量化器的信噪比,取决于特定的量化器类型。Gp为由差值量化所产生的增益。一般Gp都大于1。
图3.4中P是预测器,如采用线性预测。线性预测的基本概念是:一个语音抽样能够用过去若干个语音抽样的线性组合来逼近,即:
差值量化编码DPCM是利用样本与样本之间存在信息冗余度来进行编码的一种数据压缩技术。差值量化编码是根据过去的样本去估计下一个样本信号的幅度大小,这个值称为预测值,然后对实际信号值与预测值之间的差进行量化编码,从而就减少了表示每个样本信号的位数。它与脉冲编码调制(Pulse Code Modulation,简称PCM)不同的是,PCM直接对采样信号进行量化编码,而DPCM是对实际信号值与预测值之差进行量化编码,存储或传送的是差值而不是幅度绝对值,这样就降低了传送或存储的数据量。此外,它还能适应大范围变化的输入信号。
③ 自适应差值量化编码(ADPCM)
自适应、差值量化和线性预测从不同角度提供了改善量化器性能的途径。我们可以设计出采用自适应量化器、线性预测器的差值PCM编码器,这也称之为ADPCM编码器。由于ADPCM性能优越广泛用于音频编码中。如CCITT的32Kbit/s音频编码标准G.721.MPC中的不少音频板也提供ADPCM压缩算法,如将16位抽样压缩成4位, 8位抽样压缩成4、3或2位。
自适应差值量化编码(ADPCM)综合了APCM的自适应性和DPCM系统的差分特性,是一种性能比较好的波形编码。它的核心思想是:
・利用自适应改变量化阶距,即使用小的量化阶距去编码小的差值,使用大的量化阶距去编码大的差值。
・使用过去的样本值估算下一个输入样本的预测值,这样,可以使实际样本值和预测值之间的差值总是最小。
音频编码的分为三种类型:
・基于人的听觉特性进行编码
波形编码和参数编码是依据波形本身的相关性和模拟人的发音器官的特性进行编码的方法,而下面将介绍的是利用人的听觉系统特性来达到压缩声音数据的目的,这种压缩编码称为感知声音编码(perceptual audio coding)。