1.DSP结构
DSP是一种集成度很高的数字信号处理器,主要用于语音、图像等信号的处理。随着VLSI技术的发展,从1987年以来,DSP的产品越来越多,应用也越来越广泛。
一般DSP采用HARVARD结构(一种非传统的Von Neumann结构),其典型的HARVARD结构有一个数据存储器及一条独立的指令总线,使处理器可以从分离的存储器中并行地取指令和数据。而在 Von Neumann结构中,指令及数据存放在一个公用的存储器中,并通过同一总线存取。相比之下,HARVARD结构能够得到更高的性能和速度。
由于采用了HARVARD结构,一般DSP都具有很高的运算速度。以乘法为例,一般微处理器要用25个时钟周期完成一次乘法运算,而新一代的DSP芯片只需一个周期就可完成同种操作,运算速度达到5MIPS,最近出厂的芯片,已达到50MIPS左右。
2.专用的DSP
有些DSP芯片的结构和性能,非常适用于视觉信息低层次的处理,称为图像处理专用的DSP芯片。
视觉信息低层次处理的算法大量使用重复的乘、加运算,有些半导体公司就抓住了这个核心问题向传统计算机的运算器提出挑战,使DSP的处理速度不断提高。
例如,英国的 INMOS公司在 1987年首先推出了 IMS A100级联型信号处理器,数据吞吐速度为 10MHz。它有32个16 × 16bit的乘法器,同时还有一个 32个输入端、字长为16bit的加法器。该器件可以有效地完成离散的快速博里叶变换、相关运算及卷积运算。1988年,该公司又推出了IMS A110图像和信号处理子系统。IMS A110有一个可组合的乘法累加器阵列, 3个可编程的长度为1120级的移位寄存器,一个多功能的后处理单元及微机接口部件,能够实时完成一维l × 21、二维 3 × 7的卷积,同时还能完成大量的末端后处理工作。我们用这个器件设计了一个基于DSP的机器人视觉信号快速处理器。其他公司如Analog Devices公司的ADSP提供一个小的Cache存储器在芯片上,其他存储器通过接口实现。TI公司的TM 32030在芯片上提供RAM和ROM用于编程和数据存储。DSP芯片内部采用多数据寄存器及总线结构,使数据的运算和转换同时进行。芯片内部带有存储器占用空间,减少存取时间,加上外部的高速RAM,可以大大提高处理速度。
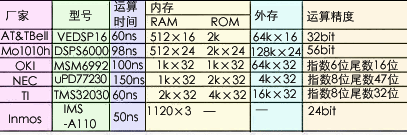
从表2.2可见,这些专用芯片的指令周期仅在60~100ns以内,可管理的RAM已从64K扩展到16M,运算精度也很高,而功耗仅为0.3~1W。如果再采用多处理器多体或级联,又可把运算速度提高一个数量级,这可能是解决视觉信号处理速度瓶颈的一个性能价格比高而又切实可行的方案。
表2.2 DSP芯片比较
3.基于DSP方法的视频信号快速处理器的设计
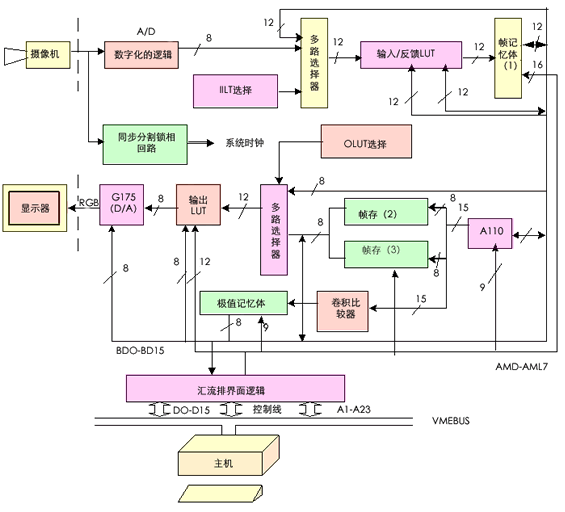
基于DSP方法的视频信号快速处理器的总体框图如图2.21所示。该处理器的核心部件是INMOS公司生产的A110,它是图像与信号高速处理专用的、可编程控制的、可级联的专用芯片。它的最大特点是具有很强的乘、加运算能力(420MOPS),同时还具有很强的图像处理功能,如图像增强、取阈值、求极大值、边线检测及数据的动或静态变换等。
图2.21 基于DSP的视频信号获取和快速处理器总体框图 (点击查看大图)
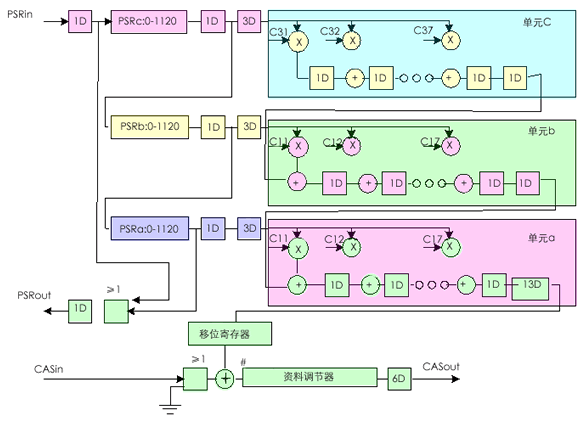
A110按其功能可分为两大部分:卷积器和后处理部件。
图2.22是A110卷积部分详细框图,共有21个乘加器,其结构是可变的,既可以是一个21级一维流水线结构,也可以编程为一个 3 × 7二维结构。它是一个典型的可变结构的Systolic阵列,在通信上采用数据串入、权值(系数)不动、结果按流水线移动的方式。数据串入是通过三个可编程(0~1120级)移位寄存器实现的。当流水线充满时,输入数据的最大速度可达20Mbyte/s,由于存储器的存取时间难于与之匹配,所以,我们选主频为 10Mbyte/s,它比A110快一倍,足以满足实时要求。
图2.22 (点击查看大图)
当做二维卷积时,假设对512×512×8bit的图像f(x,y)作3×7窗口的卷积,系数矩阵为:

在初始状态时,系数寄存器的内容,设置为
当流水线充满时,一个时钟脉冲就输出一个卷积结果
再具体一点,如果要一个3×3Sobel算子的二维卷积,只要把系数设置为

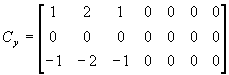
当然Sobel算子还有1/4数值,这可以通过A110的后处理部件来实现。要做一维卷积,问题就更简单了,系统按顺序置入C31~ C37,C21~ C27,C11~ C17,三个移位寄存器分别设置为0级,即能满足要求,速度仍为10Mbyte/s。
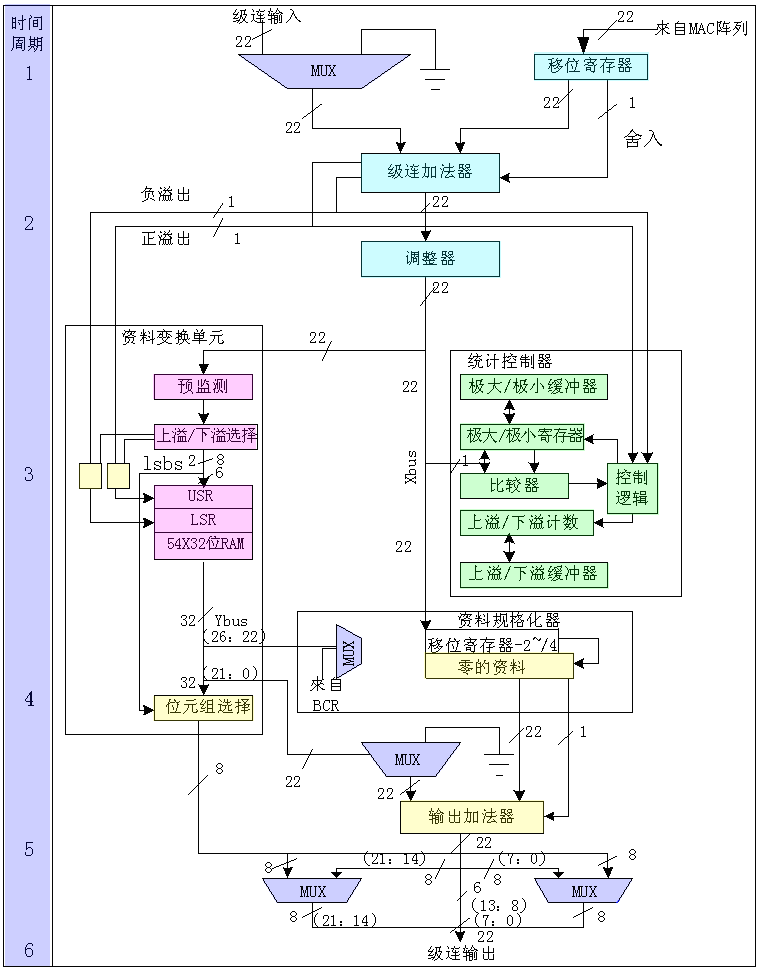
乘加运算器的结果并没有直接输出,而是经过一个后处理部件作一些必要的处理后再输出,图3.23是A110后处理部件的详细框图。从图上可见,它由多个可编程的多种开关、移位寄存器、加法器、数据变换部件、统计监控部件以及数据规格化部件组成。通过移位器,可以实现数据按比例的放大或缩小。通过级连加法器,可以进行两幅图像的加、减;通过统计监控部件,可捕获数据流的极大、极小值,还能统计比预置阈值大(或小)的像素个数。所有这些部件都可编程控制,通过各部件不同功能的组合,就可以实现一些比较经典的图像处理功能。例如,通过编程移位器和加法器,很容易实现较为复杂的数据变换,如数据的动、静态压缩和分段线性等处理。通过统计部件,级连加法器和数据规格化部件,可以方便地检测到结构光(Structure Light)的极值,检测出图像的边缘;还可以做直方图均衡化的处理。这样,既减少了主机负担,又加快了运算速度。同时,由于是在同一块芯片上实现的,所以,减少了外围电路,缩小了整板体积,增强了处理能力,提高了性能价格比。
图3.23 A110后处理部件框图 (点击查看大图)
除了A110之外,视觉快速处理器还有三个512 × 512 × 8bit的帧存储器A、B1和 B2,可以同时存放三幅8bit的图像,或一幅8bit和一幅 16bit的图像。监视器可以显示任一个存储器的内容。帧存储器选用了DRAM和VRAM两种存储器,DRAM的存取时间是120ns。我们采用了多体并行存储技术,实现了图像像素的存取时间小于100ns,满足了实时的要求。输出部分,我们选用了INMOS公司生产的 IMS G175具有 D/A变换的彩色查找表,它有一个256 × 8 × 18的查找表,输入的图像信号经过查找表变成3路RGB伪彩色数据,再经过3路D/A变换器,将数字信号变成适合彩色监视器使用的RGB模拟信号,从而产生256K种彩色。
其他的视频信号数字化部件以及主机总线接口部件已在前面讲述,它们的原理基本相同。